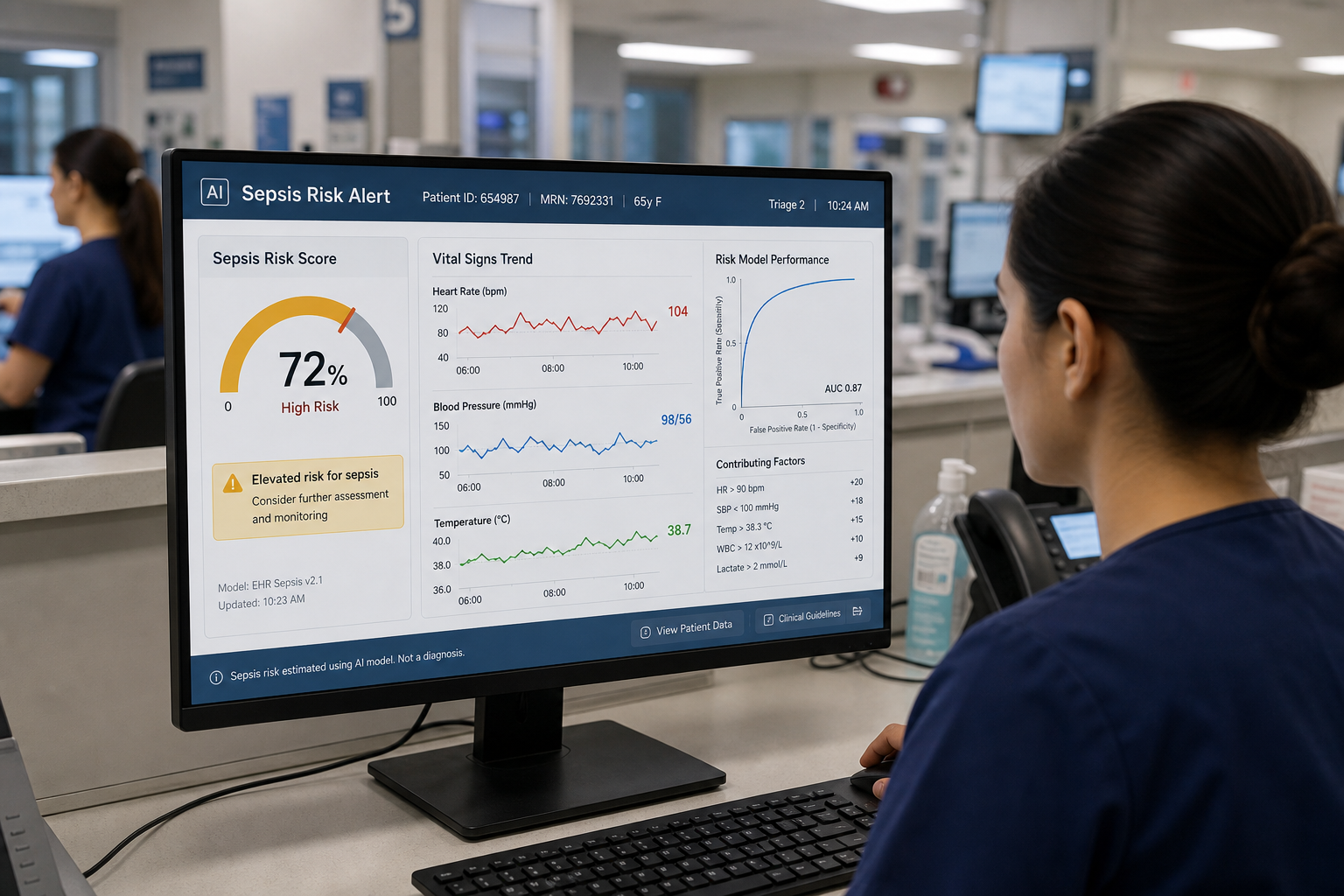

Sepsis in the Emergency Department: Why the Detection Window Matters
Sepsis kills approximately 11 million people annually worldwide. In the United States, it remains the leading cause of in-hospital death and a primary driver of ICU admissions. The mortality risk is not static — it rises by an estimated 4 to 7 percent for each hour that appropriate antibiotic therapy is delayed. That time-sensitivity makes the emergency department the most consequential point in the care continuum for sepsis detection.
The ED triage encounter is where the detection window opens. A patient arrives with a chief complaint — fever, altered mental status, back pain, generalized weakness — and a nurse documents vital signs and a brief clinical narrative. The sepsis signal, if present, is often subtle at this stage: mildly elevated heart rate, a temperature that just crosses a threshold, a triage note mentioning recent urinary symptoms. Without a structured detection mechanism, that signal competes with dozens of other patients, high cognitive load, and time pressure.
Manual screening tools exist, but clinician application is inconsistent. A patient who does not look acutely ill may not trigger sepsis consideration until laboratory results return — often an hour or more after triage. By then, the detection window has narrowed. This is the operational problem that AI-based clinical decision support is designed to address: identifying sepsis risk at triage, before clinical suspicion is formally raised, using data that is already available in the electronic health record.
Why Traditional Scoring Tools Fall Short
The most widely used sepsis screening tools in the ED — SIRS criteria, qSOFA, MEWS, and NEWS — were designed as clinical shortcuts, not as precision diagnostics. Each has documented limitations that become acute in the ED triage context.
SIRS criteria (systemic inflammatory response syndrome) are highly sensitive but poorly specific — a patient with a viral illness, a postoperative fever, or vigorous exercise can meet SIRS thresholds without sepsis. qSOFA, introduced with the Sepsis-3 definition, trades sensitivity for specificity, but this means early-stage sepsis without overt organ dysfunction is frequently missed. MEWS and NEWS incorporate more vital sign parameters but still depend on complete manual data entry and do not incorporate clinical narrative or laboratory context.
| Tool | Pooled AUROC (ED studies) | Primary Limitation |
|---|---|---|
| SIRS | 0.66–0.74 | Poor specificity; misses Sepsis-3 presentations |
| qSOFA | 0.66–0.74 | Low sensitivity for early sepsis; misses non-overt organ dysfunction |
| MEWS | 0.66–0.74 | Manual entry dependent; no free-text or lab integration |
| NEWS | 0.66–0.74 | Similar to MEWS; limited adaptability across patient subgroups |
| AI/ML models (pooled) | 0.87 (95% CI 0.86–0.88) | High heterogeneity; external validation gaps |
The quantitative gap is consistent across the literature. The 2026 Zhang et al. systematic review found that traditional rule-based methods showed pooled AUROCs in the 0.66–0.74 range — a level that, in practice, means a meaningful proportion of septic patients are not flagged in time for early intervention. The tools also share a structural problem: they require a clinician to initiate the scoring process. In a busy ED, that initiation step is itself a failure point.
AI and Machine Learning Approaches at ED Triage
AI-based sepsis detection in the ED is not a single method — it is a family of approaches that differ in the data they consume, the algorithms they apply, and the point in the clinical encounter where they generate output. Understanding these distinctions matters for clinicians evaluating tools, because a model trained on post-triage laboratory data cannot be meaningfully compared to one that operates on triage-only inputs.
Supervised Machine Learning
Gradient boosting methods — including XGBoost and LightGBM — are the most widely validated algorithm class in ED sepsis prediction. They train on structured EHR data (vital signs, demographics, laboratory values) and output a probability score. Random forest models follow a similar approach. These methods are interpretable relative to deep learning, can handle missing data reasonably well, and are computationally efficient for real-time deployment. The 2026 Zhang et al. meta-analysis found that boosting-based models achieved the highest pooled AUROC among algorithm families at 0.90 (95% CI 0.87–0.93).
Deep Learning
Long short-term memory (LSTM) networks are applied to serial vital sign data, capturing temporal patterns that single-timepoint models miss. Convolutional neural networks (CNNs) have been applied to ECG waveform analysis as a sepsis signal — a modality that is available early in many ED encounters. Deep learning approaches generally require larger training datasets and are harder to interpret, which creates challenges for clinician trust and regulatory review.
Natural Language Processing of Triage Notes
Triage nursing notes contain clinically rich information — chief complaint, symptom duration, recent history — that structured vital sign fields do not capture. NLP models extract sepsis-relevant signals from this free text and combine them with structured inputs. The most validated approach in the ED literature is a fine-tuned DistilBERT model combined with XGBoost, applied to triage notes alongside vital signs and demographics. This ensemble approach achieved AUROC 0.94 in the Brann et al. 2024 cohort study across more than one million adult ED encounters.
Input Features: Triage vs. Post-Triage
The distinction between triage-available and post-triage inputs is clinically important. A model that requires laboratory values (WBC, creatinine, lactate) to generate a prediction cannot flag sepsis at the point of triage — it flags it after the lab order has been placed and resulted, which may be 60–90 minutes later. Triage-only models sacrifice some predictive accuracy but operate at the earliest possible point in the encounter.
- Triage-available inputs: vital signs (heart rate, respiratory rate, temperature, blood pressure, oxygen saturation), age, sex, chief complaint, triage acuity level, free-text nursing notes.
- Post-triage inputs: laboratory values (WBC, creatinine, lactate, bilirubin), serial vital sign trends, medication administration records, imaging results.
- Continuous monitoring inputs: real-time vital sign streams, cumulative EHR data across the encounter — used by tools like Bayesian Health's platform that re-score patients repeatedly rather than at a single timepoint.
What the Evidence Shows: 2026 Systematic Review and Landmark Studies
The most comprehensive quantitative synthesis of AI sepsis prediction in the ED to date is the Zhang et al. 2026 systematic review and meta-analysis, published in the Journal of Medical Systems (PMID 41973329). It synthesized 36 studies comprising 98 predictive models, with a pooled AUROC of 0.87 (95% CI 0.86–0.88) — a substantial improvement over the 0.66–0.74 range reported for traditional tools.

Landmark Study: Brann et al. 2024 NLP Triage Cohort
The model — a fine-tuned DistilBERT plus XGBoost ensemble applied to triage nursing notes, vital signs, and demographics — achieved AUROC 0.94 at the point of triage, with sensitivity 0.87, specificity 0.85, and NPV 0.99. The PPV was 0.18.
The PPV figure requires careful interpretation. At 3.45% sepsis prevalence, a PPV of 0.18 means approximately 82% of positive alerts do not correspond to confirmed sepsis. This is not a failure of the model — it is a mathematical consequence of low base-rate disease in a high-volume screening context. The NPV of 0.99 means the model is highly reliable for ruling out sepsis, which has independent clinical value. But the alert burden from false positives is a real implementation challenge that any deployment must address through threshold calibration.
The study also found that the model correctly identified sepsis in 76% of cases where clinical staff had not initiated sepsis screening — demonstrating the tool's potential to surface cases that would otherwise be missed at triage. Among septic patients who subsequently required vasopressors or ICU admission, the model predicted sepsis in 97.9% and 91.6% of encounters respectively.
Cluster-RCT Evidence: Antibiotic Timing vs. Mortality
The Kijpaisalratana 2024 cluster-randomized controlled trial implemented a real-time machine learning sepsis alert integrated into an EHR. The trial found that 8.3% more patients received antibiotics within one hour of presentation in the intervention arm, and 5.5% more received them within three hours. These are clinically meaningful process improvements.
However, the trial did not demonstrate a statistically significant reduction in 30-day mortality or hospital length of stay. This gap between process improvement and outcome improvement is a recurring theme in the AI sepsis literature and should temper expectations about what an alert system alone can accomplish without accompanying workflow and treatment protocol changes.
Why AUROC Is Not Enough
Across the 36 studies in the Zhang et al. meta-analysis, almost all reported AUROC as the primary performance metric. AUROC measures a model's ability to rank positive cases above negative cases across all possible thresholds — a useful summary statistic, but one that can remain high even when a model performs poorly at the specific operating threshold used in clinical practice.
At the low prevalence of sepsis in the ED (2–4%), precision-recall curves and PPV at the chosen alert threshold are more informative for predicting alert burden. Calibration — whether the model's predicted probabilities correspond to actual event rates — determines whether clinicians can trust the numeric risk scores, not just the binary alert. These metrics are underreported in the current evidence base and should be required elements of any pre-deployment evaluation.
Deployed Tools and Regulatory Status as of Mid-2026
The regulatory landscape for AI sepsis monitoring shifted in May 2026 with the first FDA 510(k) clearance for a continuous AI sepsis monitoring system. The following profiles are based on publicly available regulatory records, peer-reviewed publications, and verified deployment reports. Regulatory clearance and clinical benefit are distinct — clearance confirms safety and performance against a regulatory standard; it does not substitute for prospective outcome evidence.
Bayesian Health
Bayesian Health received FDA 510(k) clearance (K250680) in May 2026 — the first-ever clearance for a continuous AI sepsis monitoring system. The clearance builds on a prior FDA Breakthrough Device Designation. Unlike tools that require clinical suspicion to be raised before generating an alert, the Bayesian Health platform continuously monitors all hospitalized patients and generates flags before clinical suspicion is formally documented.
The primary validation study was published in Nature Medicine in 2022 and covered 764,707 patient encounters (17,538 with sepsis) across five hospitals. When clinicians acted on the alerts, the study found 18% lower in-hospital mortality compared to encounters where alerts were not acted upon, with 82% sensitivity, a 5.7-hour lead time before clinical deterioration, and 89% provider adoption. This is an observational real-world finding, not a randomized controlled trial — the comparison group received usual care without the alert, but patients were not randomized, and confounding cannot be excluded.
At MemorialCare, a deployment report documented a 3.6% absolute reduction in mortality when providers engaged with the Bayesian flag, more than double the sensitivity of the prior sepsis screening system, time to antibiotics cut in half when the alert was acted upon within the first hour, and 90% ED adoption. These figures come from a deployment report, not a controlled trial. The tool is also deployed at Cleveland Clinic, Johns Hopkins, and University of Rochester Medicine. Starting October 2026, the FDA clearance positions Bayesian Health as eligible for CMS New Technology Add-on Payment (NTAP).
Mednition KATE
Mednition's KATE platform is an NLP-based ED triage tool that has received FDA Breakthrough Device Designation. Published research includes a 2025 study on Sepsis-3 detection in the ED using machine learning (Ivanov and Reilly) and a 2023 preprint applying machine learning with clinical NLP to sepsis detection at ED triage (Ivanov et al.). The Breakthrough Device Designation indicates FDA has recognized the tool's potential to address an unmet clinical need, but as of mid-2026 the platform does not hold full 510(k) clearance. Specific AUROC and sensitivity figures for KATE should be verified against the published studies before use in procurement evaluations.
Epic Sepsis Model: A Cautionary Example
The Epic Sepsis Model (ESM) is deployed across hundreds of U.S. hospitals and represents the most widely used AI sepsis alert in practice. Initial internal validation reported AUC of 0.76–0.83. External validation by Wong et al. (2021) revealed a performance drop to AUC 0.63, with poor calibration. At that performance level, physicians needed to evaluate 109 alert-triggered patients to detect one additional sepsis case earlier than usual care. The ESM experience illustrates the generalizability gap: a model that performs well in its training environment may perform substantially worse when deployed in a different patient population, EHR configuration, or clinical workflow.
| Tool | Regulatory Status | Validation Design | Key Performance Finding | Evidence Type |
|---|---|---|---|---|
| Bayesian Health | FDA 510(k) cleared (K250680, May 2026) | Observational, n=764,707, 5 hospitals | 18% lower in-hospital mortality when alerts acted upon; 82% sensitivity | Observational deployment study |
| Mednition KATE | FDA Breakthrough Device Designation (not yet 510(k) cleared) | Published ML + NLP studies (2023 preprint; 2025 peer-reviewed) | Performance metrics require verification from underlying publications | Peer-reviewed study + preprint |
| Epic Sepsis Model | No FDA clearance (EHR-embedded CDS) | External validation (Wong 2021) | AUC dropped from 0.76–0.83 (internal) to 0.63 (external); 109 evaluations per additional early detection | External validation study |
Known Limitations of AI Sepsis Tools in the ED
The evidence base for AI sepsis prediction in the ED is growing rapidly but carries documented limitations that clinicians and health IT teams must understand before adoption. These are not generic AI disclaimers — they are specific, documented gaps identified across the 36-study evidence base.
- Very high heterogeneity across studies. The pooled AUROC of 0.87 from the Zhang et al. 2026 meta-analysis comes with I²=99.94% — meaning the individual studies are so different in population, sepsis definition, model architecture, and validation approach that the pooled estimate is a rough directional signal, not a reliable prediction of local performance. Evidence certainty was rated low overall (GRADE).
- Lack of external validation. This is the most consistently reported gap across the 36-study evidence base. Most models were validated only in the institution where they were trained. The Epic Sepsis Model's AUC drop from 0.76–0.83 to 0.63 on external validation is the clearest documented example of what generalizability failure looks like in practice.
- Algorithmic bias is underreported. Only 1 of 36 studies in the 2026 meta-analysis explicitly addressed health-inequality considerations across sociodemographic groups. This means the evidence base provides almost no information about whether these models perform equitably across race, ethnicity, sex, age, or socioeconomic status — a critical gap given that sepsis disproportionately affects vulnerable populations.
- Alert fatigue. At 2–4% ED sepsis prevalence, even a high-sensitivity model generates many false-positive alerts. If alert thresholds are not carefully calibrated to local conditions, clinicians will begin ignoring alerts — a well-documented behavioral response that can eliminate any clinical benefit the tool provides. Alert fatigue is consistently identified as a top implementation barrier across the literature.
- Automation bias and skill erosion. With widespread AI use, there is a documented risk that clinicians over-rely on algorithmic outputs and reduce independent clinical assessment. There is also a concern about gradual erosion of the pattern-recognition skills that experienced clinicians develop through unassisted evaluation.
- PPV challenges at low prevalence. The Brann 2024 NLP study achieved AUROC 0.94 but PPV of 0.18 at 3.45% sepsis prevalence. This is not a model failure — it is a mathematical property of screening at low base rates. But it means most positive alerts will not correspond to confirmed sepsis, which has implications for workload, downstream testing, and antibiotic stewardship.
- Heterogeneous sepsis definitions. Studies use Sepsis-3 criteria, ICD-coded sepsis, SIRS-based definitions, and physician-adjudicated labels interchangeably. These definitions capture different patient populations and produce different event rates, making direct cross-study comparisons unreliable.
- Retrospective single-center design predominates. Most studies in the evidence base are retrospective and conducted at a single institution. Prospective multi-center trials with patient outcome endpoints — not just process measures — remain rare.
- Pediatric sepsis is not covered. The Brann 2024 NLP study and most other landmark studies excluded patients under 18. Pediatric sepsis presents differently and requires separate model development and validation. No ED-specific pediatric AI sepsis tool has comparable evidence.
Implementation Evidence and Professional Consensus on Clinician Oversight
Benchmark performance on retrospective data does not translate automatically into clinical benefit. The implementation context — how alerts are presented, who acts on them, how workflows are redesigned, and how governance is structured — determines whether a high-performing model improves patient outcomes or adds noise to an already complex clinical environment.
March 2026 Emergency Medicine Consensus Statement
Emergency physicians retain authority for patient care decisions. AI should enhance, not replace, clinical judgment, and any AI approach must preserve the physician-patient relationship. Physician-led governance is required.
The statement reflects a professional consensus that AI tools in the ED operate as decision support, not autonomous agents. It also signals that health systems deploying AI sepsis tools without physician-led governance structures are operating outside the professional norms established by all major emergency medicine organizations.
Documented Facilitators of Adoption
The MemorialCare deployment of Bayesian Health's tool provides one of the more detailed documented implementation accounts. Before go-live, the health system co-designed workflows with ED, inpatient, ICU, and quality teams. The result — 90% ED adoption and halved time to antibiotics when alerts were engaged within the first hour — reflects what structured workflow integration can produce. The CMO noted that clinicians were working with significantly fewer electronic alerts, which helped restore trust in the AI tool.
- Workflow co-design before deployment, not after — involving ED nurses, physicians, pharmacists, and quality teams in alert design and threshold calibration.
- Dedicated nursing intermediaries who receive and triage AI alerts before escalating to physicians, reducing the alert burden on physicians directly.
- Explainability tools — such as heat maps showing which features drove a specific alert — that allow clinicians to evaluate the alert in clinical context rather than accepting or rejecting a black-box score.
- Post-encounter feedback loops that inform clinicians of patient outcomes following alerts they acted on or dismissed, supporting learning and calibration of clinical judgment over time.
- Alert threshold calibration to local sepsis prevalence and workflow capacity, rather than using default thresholds from the training environment.
Documented Barriers
- Clinician unfamiliarity with the underlying model — when clinicians do not understand how an alert is generated, they are less likely to trust it and more likely to dismiss it without evaluation.
- 'Black box' distrust — the absence of explainability features is consistently associated with lower adoption and higher alert dismissal rates in the implementation literature.
- Alert fatigue from poorly calibrated thresholds — models deployed with default thresholds from training environments generate alert volumes that EDs cannot operationally absorb, leading to systematic dismissal.
Evaluation Framework: Questions to Ask Before Deploying an AI Sepsis Tool
The following framework is intended for emergency medicine clinical leaders, clinical informaticists, and health IT teams conducting pre-deployment evaluation of AI sepsis CDS tools. It is a structured set of questions, not a product recommendation or endorsement of any specific tool.
| Evaluation Domain | Questions to Ask | Why It Matters |
|---|---|---|
| External Validation | Has the model been validated on a patient population similar to yours in demographics, case mix, and EHR system? What was the AUROC, sensitivity, specificity, and PPV in that validation? | Internal validation AUROCs routinely exceed external validation performance. The Epic Sepsis Model's AUC dropped from 0.76–0.83 to 0.63 on external validation. |
| PPV at Local Prevalence | What is the expected PPV at your ED's actual sepsis prevalence? How many false-positive alerts per day will your clinical team receive? | At 2–4% sepsis prevalence, even high-sensitivity models generate high false-positive volumes. Alert burden determines whether clinicians engage or dismiss. |
| Alert Threshold Calibration | Who controls the alert threshold? Can it be adjusted after deployment? What is the methodology for setting and recalibrating thresholds over time? | Default thresholds from training environments are rarely optimal for a new ED. Local calibration is essential to managing alert fatigue. |
| Post-Market Monitoring | Does the vendor have a documented post-market surveillance plan? How is model drift detected and addressed? Who is notified when performance degrades? | Model drift — performance degradation as patient populations or care patterns change — is a documented risk in deployed AI. No monitoring plan means no safety net. |
| EHR Integration | How does the tool integrate with your EHR? Is it embedded in existing workflows or a separate interface? What data inputs does it require, and are those reliably available at your site? | Integration failures — missing data fields, latency in data feeds, alert display in non-standard locations — are common causes of poor adoption in real-world deployments. |
| Governance and Audit | Who in your organization owns the AI sepsis tool? Is there a physician-led governance committee? How are alert dismissal patterns, outcome data, and safety incidents reviewed? | The March 2026 ACEP consensus statement requires physician-led governance for AI in emergency medicine. Health systems without governance structures are operating outside professional consensus. |
| Explainability | Does the tool show clinicians which factors drove a specific alert? Can clinicians interrogate the reasoning behind a high-risk flag? | Explainability features are consistently associated with higher adoption and more appropriate alert response. Black-box scores generate distrust and dismissal. |
| Regulatory Status | Is the tool FDA-cleared, and for what intended use? Does the intended use match your deployment context? If not cleared, what is the regulatory pathway and timeline? | FDA clearance (510(k), De Novo, or PMA) confirms safety and performance against a regulatory standard. It does not confirm clinical outcome benefit. Intended use scope matters — a tool cleared for inpatient monitoring may not be cleared for ED triage specifically. |
| Equity and Bias | Has the tool been evaluated for differential performance across race, ethnicity, sex, age, and insurance status? Are subgroup performance metrics available? | Only 1 of 36 studies in the 2026 meta-analysis addressed algorithmic bias. Differential performance across patient subgroups is a documented risk that vendors should be able to address with data. |
| Pediatric Applicability | Is the tool validated for pediatric patients? If your ED treats children, does the vendor have separate pediatric validation data? | Most AI sepsis tools, including the leading NLP models, were developed and validated on adult populations only. Pediatric sepsis has different clinical presentations and requires separate evidence. |
Comments
Join the discussion with an anonymous comment.