
ESM as a Governance Case Study, Not Just a Failed Model
Sepsis kills an estimated 270,000 Americans annually and accounts for more than one-third of in-hospital deaths in the United States. The clinical imperative to detect it earlier is real, urgent, and well-documented. That imperative is precisely what made the Epic Sepsis Model's rapid adoption so comprehensible — and its governance failure so consequential.
This article does not primarily ask whether ESM is a good model. That question — with its AUROC figures, sensitivity thresholds, and alert burden calculations — is addressed in detail in the clinical evidence brief on AI sepsis prediction tools. This article asks a different question: how did a proprietary clinical prediction tool reach hundreds of US hospitals before any independent external validation was published, and what does that sequence reveal about the governance structures that clinical AI deployment currently lacks?
The distinction matters because the ESM controversy is not an isolated incident. It is a paradigmatic case study — one with unusually complete documentation — of the structural conditions that allow algorithmic tools to scale inside clinical environments before accountability mechanisms engage. Four structural mechanisms made this possible, and each has direct implications for governance reform:
- EHR bundling dynamics that made ESM adoption a default rather than a deliberate procurement decision.
- Proprietary trade-secret designation that blocked independent testing before deployment.
- Financial incentives to hospitals that accelerated adoption without requiring performance evidence.
- The absence of any regulatory or professional body requirement for pre-deployment external validation of EHR-embedded clinical prediction tools.
Understanding the ESM arc — from unchecked deployment to external scrutiny to partial redesign to persistent structural limitations — provides a concrete, evidence-grounded foundation for what responsible clinical AI governance should require. For readers who want foundational context on how AI tools function across clinical applications broadly, that context is available separately. This article proceeds directly to the governance argument.
How ESM v1 Reached Scale Before External Validation
Epic Systems serves approximately 54% of US patients through its EHR platform. That market position is not incidental to the ESM story — it is the mechanism. When a tool is embedded in the dominant EHR platform and offered as a packaged feature rather than a separately procured product, adoption decisions are structurally different from standard medical device procurement.
ESM v1 was released in 2017–2018, trained on approximately 500,000 internal encounters at Epic-affiliated institutions. No peer-reviewed external validation study appeared in the literature before the model was already running in hundreds of hospitals. The tool was designated a proprietary trade secret, which meant that the predictor variables, model architecture, and internal validation methodology were not available for independent review.
The financial dimension compounded the adoption dynamic. Documentation reviewed in the UT Austin ethics case study on ESM transparency indicates that Epic paid various hospitals up to $1 million each to adopt ESM. Financial incentives of that magnitude create institutional pressure to activate a tool before clinical leadership has conducted independent performance assessment — and, in the absence of any regulatory requirement to do so, many did not.
No FDA regulation, no professional society guideline, and no hospital accreditation standard required external validation before activating ESM. Clinical informaticists and quality officers who wanted independent performance data before deployment had no mechanism to compel it and no regulatory body to appeal to. The model's trade-secret status meant that even internal review of its predictor variables was not possible without Epic's disclosure.
This is the governance failure: not that Epic built an imperfect model, but that the structural environment allowed an imperfect model to reach hundreds of clinical environments before imperfection was measurable. The broader dynamics of how AI tools actually reach clinical deployment — including the role of EHR platform bundling — reflect incentive structures that are not unique to sepsis prediction.
What the 2021 External Validation Revealed — and Why It Matters for Governance
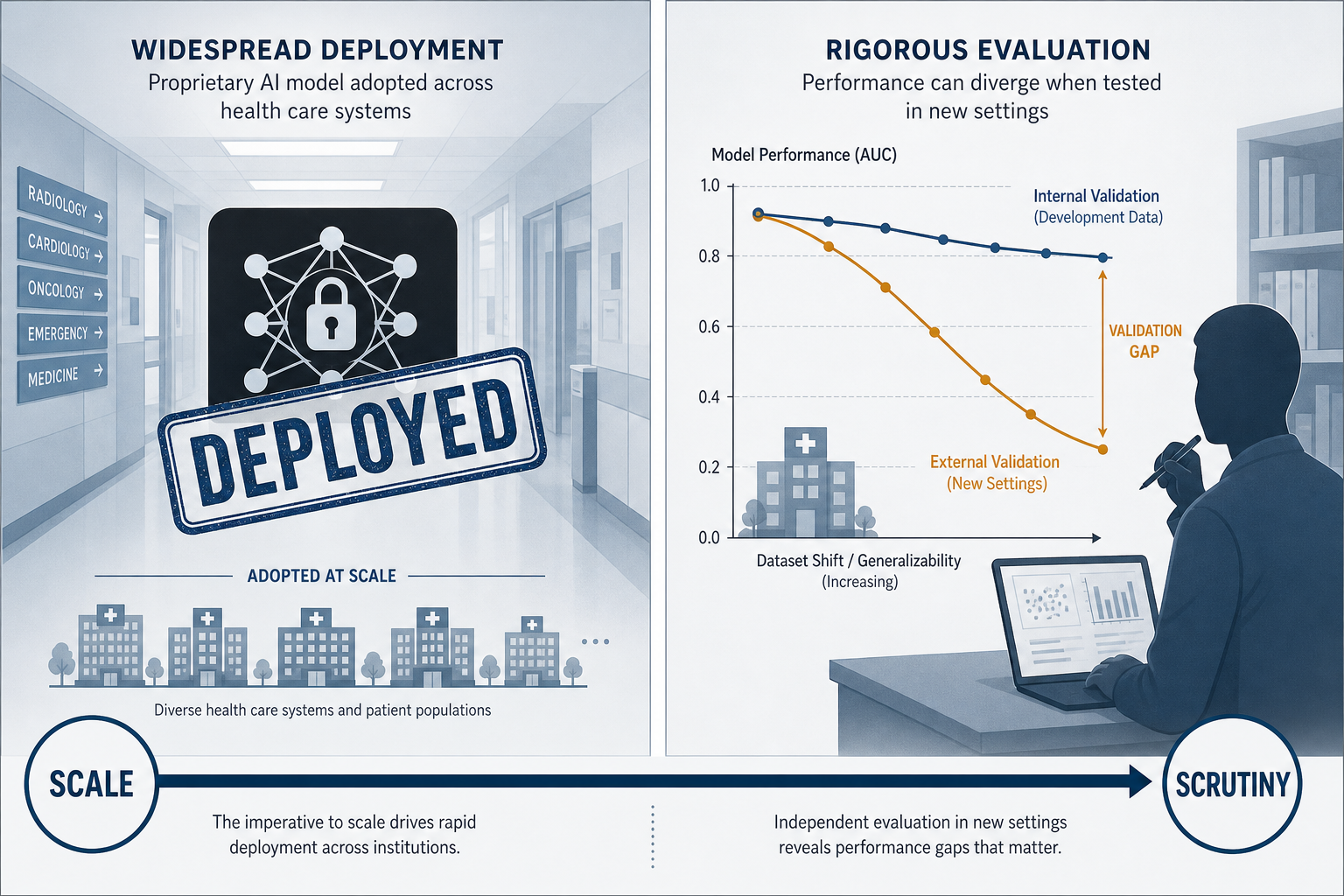
When Wong et al. published their external validation of ESM v1 in JAMA Internal Medicine in 2021, the findings were not a minor adjustment to Epic's performance claims. They were a structural indictment of the pre-deployment validation process that had not occurred.
Across 27,697 patients at Michigan Medicine, the study found an AUROC of 0.63 — substantially below Epic's claimed range of 0.76–0.83. The model missed two-thirds of sepsis cases. At the threshold score of 6 or higher, ESM generated alerts on 18% of all hospitalized patients while identifying only 7% of clinician-missed sepsis cases. Clinicians needed to evaluate 109 patients for each additional sepsis case detected — a number needed to evaluate (NNE) of 109 that makes the alert's clinical utility difficult to defend.
| Metric | Epic Internal Claim | Wong et al. 2021 External Validation |
|---|---|---|
| AUROC | 0.76–0.83 | 0.63 |
| Sepsis cases missed | Not disclosed | ~67% (two-thirds) |
| Alert rate (all hospitalized patients) | Not disclosed | 18% |
| Number needed to evaluate (NNE) | Not disclosed | 109 |
| Clinician-missed sepsis identified | Not disclosed | 7% |
Each of these findings maps to a specific governance failure, not merely a model deficiency. The AUROC gap between internal and external validation is what mandatory pre-deployment external validation is designed to surface before widespread adoption. The alert rate on 18% of hospitalized patients is what pre-specified alert burden thresholds are designed to prevent. The NNE of 109 is what happens when a tool is deployed at scale without workflow governance standards.
The antibiotic predictor finding was particularly significant from a methodological transparency standpoint. ESM v1 used antibiotic administration as one of its predictor variables. Because antibiotic administration is itself a clinical response to suspected sepsis, including it as a predictor creates circularity: the model partially predicts sepsis by detecting that clinicians are already treating for sepsis. This inflated internal validation performance in ways that external validation at a different institution — with different antibiotic prescribing patterns — would not replicate. A pre-deployment disclosure requirement equivalent to TRIPOD+AI reporting standards would have surfaced this predictor variable before deployment.
Medical professional organizations constructing national guidelines should be cognizant of the broad use of these algorithms and make formal recommendations about their use.
That call, documented in reporting on the 2021 validation, has not been fully answered as of 2026. Epic publicly disputed the Wong et al. methodology, arguing the model required institution-specific tuning. That response itself illustrates a governance gap: when a proprietary tool's developer disputes external validation findings without disclosing the model's internal architecture, there is no independent arbitration mechanism to adjudicate the disagreement.
The 2021 findings were not isolated. Lyons et al. (JAMA Internal Medicine 2023) evaluated ESM v1 across 806,696 encounters at nine networked hospitals within a single health system and found C-statistics ranging from 0.55 to 0.73. The variation was not random: C-statistics were negatively correlated with sepsis incidence (r = −0.80), comorbidity burden (r = −0.78), and cancer prevalence (r = −0.86). The model performed best at lower-acuity hospitals with lower baseline sepsis rates — the settings where the clinical need for a prediction tool is arguably least acute. This pattern of performance inversely correlated with clinical complexity is a governance-relevant finding: it means the institutions most likely to benefit from sepsis prediction support are those where ESM v1 performed worst.
ESM v2: Meaningful Improvement, Persistent Structural Problems
Epic released ESM v2 in 2022 with substantive methodological changes. The model architecture shifted from logistic regression to a gradient-boosted tree. The antibiotic administration predictor was removed. The outcome definition was updated to align with Sepsis-3 criteria. Critically, the new version supports local fine-tuning on institution-specific historical data — a direct response to the external validation criticism that a single national model could not account for institutional variation in patient population and clinical practice.
The February 2026 multicenter prospective validation by Wong et al. in JAMA Network Open — covering 227,091 inpatient encounters across four major US health systems — provides the first large-scale independent external validation of ESM v2. The headline finding is genuine improvement: AUROC ranged from 0.82 to 0.92 across the four sites, a substantial advance over the 0.63 recorded for v1 at Michigan Medicine.
But the same study reveals that improvement is not resolution. Several structural problems persist, and they are directly relevant to governance.

| Metric | ESM v1 (2021 External Validation) | ESM v2 (2026 Multicenter Validation) |
|---|---|---|
| AUROC range across sites | 0.55–0.73 (Lyons 2023, 9 hospitals) | 0.82–0.92 (Wong 2026, 4 health systems) |
| Threshold score at 60% sensitivity | Not reported | 14 to 37 (range across institutions) |
| Positive predictive value (PPV) | Not reported | 0.13–0.26 |
| Number needed to evaluate (NNE) | 109 (Wong 2021) | 4–8 (hospitalization-wide horizon) |
| First-hour CBC exclusion rate | Not applicable | 9.8%–30.1% of sepsis-positive encounters by site |
| Organizations still using v1 (as of Aug 2025) | N/A | >100 organizations |
The threshold score variability is particularly striking. To achieve 60% sensitivity, the required alert threshold ranged from 14 at one institution to 37 at another. This means that a score-based alert policy that is appropriately calibrated at one site would either miss the majority of sepsis cases or generate an unmanageable alert burden at a different site. This is not a model deficiency that local fine-tuning fully resolves — it reflects the fundamental heterogeneity of sepsis epidemiology and patient populations across institutions.
The first-hour complete blood count (CBC) exclusion is a different kind of structural problem. ESM v2 requires a CBC result within the first hour of encounter to generate a score. At some institutions in the 2026 validation, this exclusion criterion eliminated between 9.8% and 30.1% of sepsis-positive encounters — patients who developed sepsis but for whom the model never generated a score because the CBC timing criterion was not met. This limitation is absent from public-facing model descriptions and represents exactly the kind of operational constraint that pre-deployment disclosure requirements should surface.
ESM v2 is a meaningfully better model than v1. It is not a resolved problem. The 2026 validation authors themselves state that institutions implementing this model should conduct local validation studies to verify performance, integrate clinical workflows to manage false positives, and implement alert silencing strategies — and that ESM v2 is 'commonly implemented by health systems without internal validation, potentially compromising sepsis care.' That sentence, from the most favorable external validation of the model to date, is a governance indictment.
Systemic Governance Gaps the ESM Arc Exposes
The ESM story is not primarily about Epic's choices. It is about the structural environment in which those choices were made — an environment that provided no mandatory checkpoints between internal development and widespread clinical deployment. Five distinct governance gaps are visible in the ESM arc.
1. The FDA SaMD Regulatory Gap for EHR-Bundled Tools
The FDA's Software as a Medical Device (SaMD) framework applies to AI/ML tools that meet the definition of a medical device. However, as Schinkel et al. (2023) document, current regulatory frameworks are designed for locked algorithms — tools whose logic does not change after authorization. EHR-embedded proprietary clinical prediction tools that support local fine-tuning, like ESM v2, operate in a regulatory gray zone where the FDA's locked-algorithm oversight model does not straightforwardly apply.
The contrast with FDA-authorized tools is instructive. The Sepsis ImmunoScore (Prenosis) received FDA De Novo marketing authorization in April 2024 as the first FDA-authorized AI diagnostic tool for sepsis. The authorization required documented derivation, internal validation, and external validation performance data, and it explicitly prohibits local calibration or model adjustment. The regulatory process that produced that authorization — with its transparency requirements and performance documentation — is precisely what ESM's EHR-bundled deployment path bypassed entirely.
2. TRIPOD+AI Reporting Standards Apply to Publications, Not Pre-Deployment Disclosure
TRIPOD+AI (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis, extended for AI) establishes reporting standards for peer-reviewed publications about clinical prediction models. The 2026 Wong et al. validation study was conducted under TRIPOD+AI guidance. But TRIPOD+AI applies to what researchers report in journals — not to what vendors must disclose before deploying proprietary tools in clinical environments.
ESM v1's antibiotic predictor circularity would have been disclosed under TRIPOD+AI-equivalent standards. The first-hour CBC exclusion rate in ESM v2 is documented in the 2026 peer-reviewed validation but was not part of Epic's public-facing model description before deployment. The gap between publication reporting standards and pre-deployment proprietary disclosure requirements is a structural governance problem that applies to any EHR-embedded clinical prediction tool.
3. Alert Burden as an Underregulated Patient Safety Dimension
Alert burden is often discussed as a workflow problem or a clinician satisfaction issue. It is also a patient safety issue, and it is currently underregulated. When a sepsis alert fires on 18% of all hospitalized patients with an NNE of 109, the downstream consequences include antibiotic overuse, unnecessary laboratory workups, and the behavioral desensitization that reduces clinician responsiveness to alerts that are clinically meaningful.
Schinkel et al. explicitly note that sepsis alerts triggering one-size-fits-all protocols 'may lead to substantial overuse of antibiotics, with profound implications.' No regulatory standard, accreditation requirement, or professional guideline currently mandates that health systems establish pre-specified alert burden thresholds before activating a clinical prediction tool. Alert burden governance is treated as an operational decision, not a patient safety requirement.
4. Equity Audit Gaps
The 2026 ESM v2 validation conducted a fairness audit — a methodological advance over ESM v1's external validation. The audit found that model performance closely tracks baseline sepsis rate across demographic subgroups, without major independent subgroup deviations. This is a reassuring finding at the population level, but it raises a specific governance concern: if model performance is primarily determined by institutional sepsis incidence rather than by patient demographic characteristics, then the institutions where ESM v2 performs worst are high-acuity, high-comorbidity institutions that serve complex patient populations — including academic medical centers and safety-net hospitals. Equity audits need to assess not just subgroup performance within a site but differential performance across institution types that serve different patient populations.
5. Absence of RCT-Level Mortality Evidence
No sepsis AI prediction tool has demonstrated mortality benefit in a large-scale multicenter randomized controlled trial. This is not a criticism unique to ESM — it applies to the entire sepsis AI field. The strongest evidence for any sepsis AI tool is the TREWS stepped-wedge observational study published in Nature Medicine in 2022, which remains observational. The single-center before-and-after study by Cull et al. reported a 44% reduction in odds of sepsis-related mortality after ESM alert implementation (OR 0.56), but the authors explicitly acknowledged it as 'an uncontrolled before-and-after study, inherently susceptible to bias' and called for more rigorous controlled design. The governance implication is that health systems are making deployment decisions — affecting thousands of patients — based on a class of evidence that the field's own researchers describe as insufficient.
This evidentiary gap connects to the broader problem of what the evidence actually shows for AI in medical diagnosis — a gap that governance frameworks must acknowledge rather than paper over with AUROC figures.
A Governance Framework for EHR-Embedded Clinical AI Prediction Tools
The ESM arc does not just diagnose governance failures — it specifies what governance structures should require. The following framework translates ESM's documented failures into concrete institutional requirements. These are not aspirational principles; they are specific operational checkpoints that health systems can implement as procurement and activation standards.
| Governance Requirement | ESM Failure It Addresses | Operational Standard |
|---|---|---|
| Mandatory local validation before activation | ESM v1 deployed without any external validation; ESM v2 'commonly implemented without internal validation' | Pre-specified AUROC, sensitivity, and PPV thresholds must be met on local historical data before activation. Validation dataset must be prospective or held-out, not the training set. |
| Pre-specified alert burden thresholds | ESM v1 alerted on 18% of hospitalized patients with NNE 109; ESM v2 PPV 0.13–0.26 | Alert rate per 100 admissions and NNE must be defined as go/no-go criteria before activation. Thresholds trigger mandatory workflow review if exceeded post-deployment. |
| TRIPOD+AI-equivalent pre-deployment disclosure | ESM v1 antibiotic predictor circularity not disclosed; ESM v2 CBC exclusion rate not in public-facing documentation | Vendor must provide complete predictor variable list, training dataset characteristics, internal validation methodology, and known operational exclusion criteria before procurement. |
| Mandatory post-market surveillance with re-evaluation triggers | No mechanism to require ESM v1 upgrade despite documented external validation failure | Quarterly performance monitoring against pre-specified thresholds. Defined triggers (AUROC drop >0.05, alert rate increase >20%) require automatic re-evaluation and vendor notification. |
| Equity auditing tied to local patient population | ESM v2 fairness audit found performance tracks baseline sepsis rate, disadvantaging high-acuity institutions | Equity audit must assess performance stratified by race, ethnicity, comorbidity burden, and insurance status using the institution's own patient population — not a national reference dataset. |
| Procurement accountability for validation claims | Epic's internal validation (AUROC 0.83–0.86 for v2) presented without independent corroboration | Procurement documentation must distinguish vendor-provided internal validation from independent peer-reviewed external validation. Vendor claims without independent corroboration must be labeled as such. |
Implementing this framework requires changes at multiple institutional levels. Procurement teams need to add validation disclosure requirements to vendor contracts. Clinical informatics and quality teams need to conduct local validation studies before activation — not after. IT governance committees need to define alert burden thresholds as patient safety parameters, not workflow preferences. And health system leadership needs to treat post-market surveillance as an ongoing operational requirement, not a one-time implementation review.
What Responsible EHR-Embedded AI Adoption Looks Like: Lessons Beyond Sepsis
The ESM governance failure is not a sepsis-specific problem. It is a clinical AI deployment problem that sepsis prediction makes unusually visible because the external validation evidence is unusually complete.
Any EHR-embedded clinical prediction tool that benefits from the market position of its host platform faces the same structural incentive misalignment: the platform vendor has commercial interests in adoption, the hospital has financial incentives to activate features that come with the platform, and the regulatory environment currently provides no mandatory checkpoint between internal development and clinical deployment. The ESM arc — scale before scrutiny, controversy, partial redesign, continued structural limitations — is not a sequence unique to Epic or to sepsis. It is the default sequence when governance structures are absent.
The governance argument applies with equal force to clinical prediction tools for deterioration, readmission, length of stay, and any other outcome where EHR-embedded algorithmic tools are offered as bundled features rather than independently procured medical devices.
For ESM v2 specifically, the 2026 multicenter validation provides a basis for conditional responsible deployment — not unconditional endorsement. The conditions under which ESM v2 can be responsibly activated are specific:
- Local validation has been conducted on institution-specific historical data, and AUROC, sensitivity, and PPV meet pre-specified thresholds for the institution's patient population.
- The threshold score at the target sensitivity level has been established locally — not assumed from the national model default — given the documented range of 14 to 37 across the 2026 validation sites.
- The first-hour CBC exclusion rate has been quantified for the institution, and clinical workflows account for the proportion of sepsis-positive encounters the model will never score.
- Alert burden thresholds (alert rate per 100 admissions, NNE) have been pre-specified and are monitored prospectively with defined re-evaluation triggers.
- An equity audit has been completed using the institution's own patient population, stratified by comorbidity burden and demographic characteristics.
The conditions under which ESM v2 should not be activated are equally specific: when local validation has not been conducted, when alert burden thresholds have not been pre-specified, when the institution's patient population includes high comorbidity burden that the 2026 validation evidence suggests is associated with weaker model performance, or when the clinical workflow infrastructure to manage false positives at the expected PPV of 0.13–0.26 is not in place.
Comments
Join the discussion with an anonymous comment.