
Why This Review Matters: Pathology AI at a Critical Juncture
Pathology departments in many health systems are operating under sustained workforce pressure. Specialist shortages, rising case volumes, and the logistical demands of large-scale cancer screening programs have created genuine demand for tools that can assist pathologists in reviewing digitized tissue slides. Whole slide imaging (WSI) — the technology that converts glass slides into high-resolution digital files suitable for remote review and computational analysis — has made AI-assisted histopathological diagnosis technically feasible at scale.
The appeal is straightforward: if an AI model can reliably identify malignant tissue patterns in a digitized slide, it could triage cases, flag high-priority specimens, reduce inter-observer variability, and extend diagnostic capacity to settings where specialist pathologists are scarce. Vendors and research groups have reported performance figures that, on their face, appear to rival or exceed human diagnostic accuracy across multiple cancer types.
What has been missing, until recently, is a rigorous cross-disease synthesis of that evidence — one that applies consistent methodological standards to ask not just whether AI performs well in individual studies, but whether those studies are designed well enough for their results to be trusted. McGenity et al. (npj Digital Medicine, 2024) is the first systematic review and meta-analysis to attempt exactly that across multiple disease areas using whole slide images. The findings are simultaneously encouraging and sobering, and they carry direct implications for how clinicians, laboratory administrators, and procurement teams should interpret AI pathology performance claims.
Study Design and Evidence Standards
McGenity et al. conducted a systematic review and meta-analysis of AI diagnostic accuracy studies in digital pathology, following PRISMA-DTA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses of Diagnostic Test Accuracy) guidelines. The review searched PubMed, EMBASE, and CENTRAL through June 2022 — a temporal scope that must be held in mind throughout: post-2022 studies, including those involving foundation models and prospective clinical validations, fall outside this evidence base.
The screening funnel moved from 2,976 identified studies to 100 included in the systematic review to 48 included in the meta-analysis. The 52 studies excluded from meta-analysis were excluded primarily because of deficient data reporting — a finding that is itself an evidence quality signal. The 100 included studies collectively encompassed more than 152,000 WSIs drawn from multiple countries, with the United States and China as the dominant contributors to the evidence base.
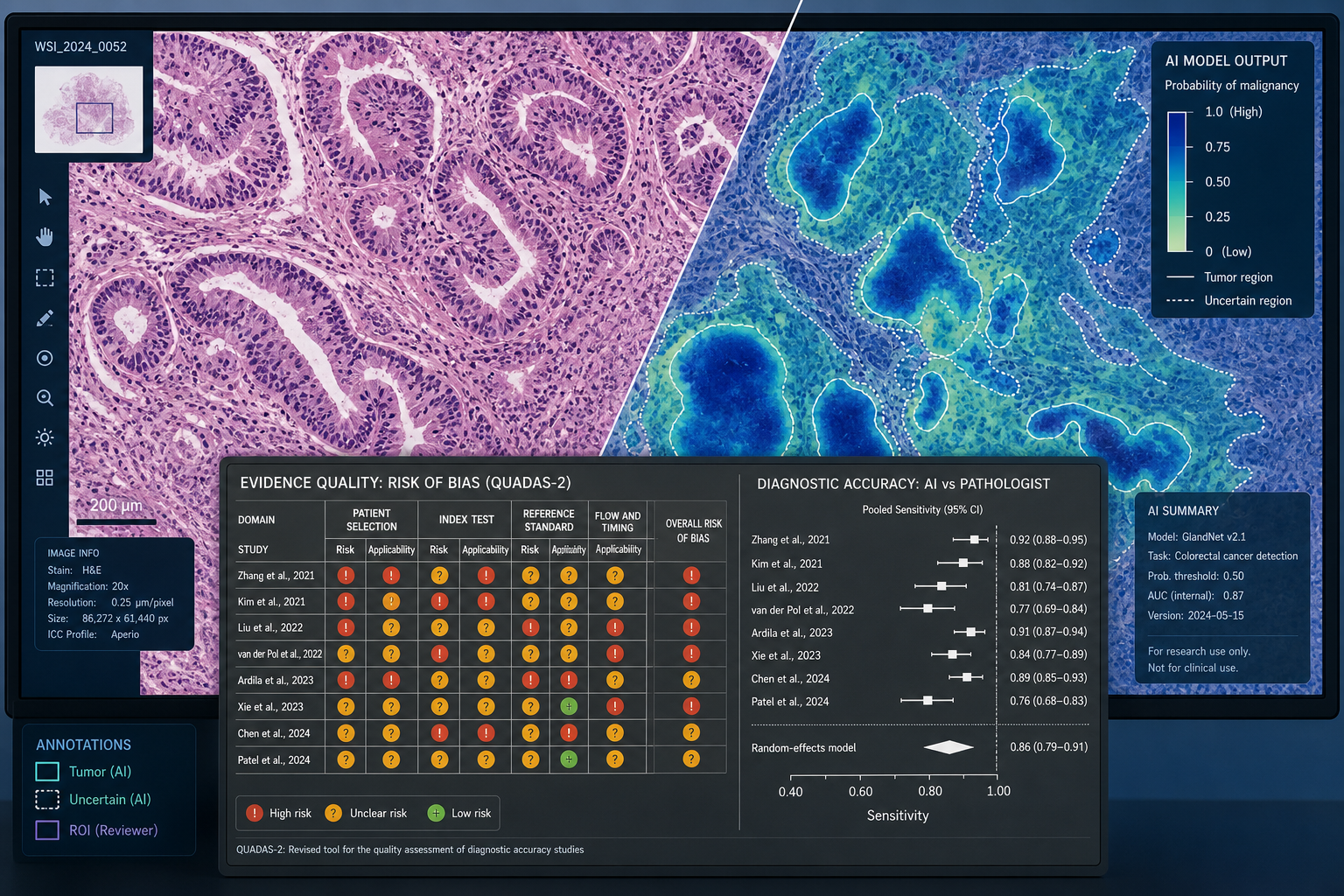
Performance was synthesized using a bivariate random effects model, which is the standard approach for diagnostic test accuracy meta-analyses because it simultaneously models sensitivity and specificity while accounting for the trade-off between them. Risk of bias was assessed using the QUADAS-2 framework, which evaluates four domains: patient selection, index test conduct and interpretation, reference standard conduct and interpretation, and flow and timing.
- Search scope: PubMed, EMBASE, CENTRAL — records through June 2022 only
- Screening funnel: 2,976 identified → 100 included in review → 48 included in meta-analysis
- Data scale: 152,000+ WSIs across multiple countries
- Performance model: bivariate random effects meta-analysis
- Bias framework: QUADAS-2 across four domains
- Reporting standard: PRISMA-DTA
- Dominant geographic contributors: USA and China
Performance Findings: Overall and by Subspecialty
Across the 48 meta-analyzed studies, the bivariate random effects model returned a pooled mean sensitivity of 96.3% (95% CI 94.1–97.7%) and a pooled mean specificity of 93.3% (95% CI 90.5–95.4%). The mean F1 score across studies reporting it was 0.87, with a range of 0.43 to 1.0 — a spread that itself indicates substantial variation in model quality beneath the aggregate figure.
These numbers are high. They are also, as the following section will establish, unreliable as clinical benchmarks. The performance and bias findings are structurally inseparable: presenting the table below without the context of near-universal evidence quality concerns would misrepresent what the review actually demonstrates.
| Subspecialty | Models (n) | Sensitivity | Specificity |
|---|---|---|---|
| Gastrointestinal pathology | 14 | 93% | 94% |
| Uropathology | 8 | 95% | 96% |
| Breast pathology | 8 | 83% | 88% |
| Hepatobiliary pathology | 5 | 90% | 87% |
| Dermatopathology | 4 | 89% | 81% |
| Cardiothoracic pathology | 3 | 98% | 76% |
| Haematopathology | 3 | 95% | 86% |
| Gynaecological pathology | 2 | 87% | 83% |
| Soft tissue and bone pathology | 1 | 98% | 94% |
| Head and neck pathology | 1 | 98% | 72% |
| Neuropathology | 1 | 100% | 95% |
Cancer-focused models outperformed non-cancer models on sensitivity (92% vs. 76%) with comparable specificity (89% vs. 88%). However, only two non-cancer models were included in the meta-analysis — a sample too small to draw reliable comparative conclusions. The near-complete absence of non-cancer disease evidence is itself a major gap addressed separately below.
Risk of Bias: Why 99% of Studies Raise Concerns
The central analytical finding of this review is not the performance figures — it is the evidence quality assessment. Of 100 studies included in the systematic review, 99% demonstrated at least one area at high or unclear risk of bias or applicability concern under QUADAS-2. Among the 48 meta-analyzed studies, the rate was 98%. These are not marginal concerns about minor methodological details; they reflect fundamental problems in how most AI pathology studies are designed, conducted, and reported.

Breaking down the four QUADAS-2 domains reveals where the problems concentrate:
| QUADAS-2 Domain | High or Unclear Risk Rate | Primary Concern |
|---|---|---|
| Patient selection | 88% | Non-consecutive or unclear case selection; retrospective case-control enrichment |
| Index test | 69% | Absence of external validation; ambiguity in training/test data separation |
| Reference standard | 33% | Unclear reference standard conduct or interpretation |
| Flow and timing | 77% | Unclear timing between index test and reference standard; 37 of 48 studies at unclear risk |
Patient selection bias is the most pervasive concern. When studies select cases non-consecutively — or when the selection process is simply not described — the resulting sample may not reflect the distribution of cases a deployed AI system would actually encounter. A model evaluated on a curated set of clear positives and clear negatives will appear more accurate than the same model facing the ambiguous, heterogeneous cases that populate routine clinical practice.
Index test concerns center primarily on the absence of external validation and on ambiguity about whether training and test data were properly separated. A model tested on data drawn from the same institution, scanner, and staining protocol as its training set will almost always appear more accurate than when applied to slides from a different clinical environment. Without external validation, reported accuracy figures reflect performance under optimal, controlled conditions — not conditions that resemble deployment.
"The consequence of identifying so many studies with areas of concern means that if the work were to be replicated with these concerns addressed, there is a risk that a lower diagnostic accuracy performance would be found." — McGenity et al., npj Digital Medicine, 2024 (PMC11069583)
The authors' own statement is unambiguous: the headline performance figures may not survive replication under methodologically rigorous conditions. Publication bias compounds this problem — studies with lower diagnostic accuracy are less likely to be published, meaning the literature systematically overstates AI performance across the board.
What Moderates Performance: External Validation and Data Source Diversity
The review identified two study-level characteristics associated with higher diagnostic accuracy: external validation and the number of data sources used for training and testing. Both findings are actionable for readers evaluating AI pathology evidence claims.
Models with external validation — tested on data from an institution or cohort separate from the training source — consistently outperformed those without it. Externally validated models achieved sensitivity of 95% and specificity of 92%, compared with sensitivity of 91% and specificity of 87% for models tested only on internal data. That gap may appear modest in percentage terms, but it reflects a meaningful difference in how well a model is likely to generalize beyond its development environment.
Data source diversity showed a similar pattern. Models trained and tested on data from a single source achieved sensitivity of 89% and specificity of 88%. Models drawing on three sources reached sensitivity of 93% and specificity of 92%. Multi-source training appears to reduce overfitting to the specific slide preparation, scanner characteristics, and staining protocols of a single institution.
- External validation present: Sensitivity 95% / Specificity 92%
- External validation absent: Sensitivity 91% / Specificity 87%
- 1 data source: Sensitivity 89% / Specificity 88%
- 3 data sources: Sensitivity 93% / Specificity 92%
The review also found that slide-level and patch-level analysis approaches produced broadly comparable performance, suggesting that the unit of analysis is not the primary driver of accuracy differences across studies. Design quality and data diversity appear more consequential than the choice of analytical granularity.
Evidence Gaps: Disease Areas and Reporting Standards
The 100 included studies and 48 meta-analyzed models do not represent the full range of pathology practice. Several structural gaps in the evidence base limit how broadly the review's conclusions can be applied.
- Non-cancer diseases are severely underrepresented: only 2 of the 50 meta-analysis models addressed non-cancer conditions. The vast majority of AI pathology research has focused on cancer detection and classification, leaving inflammatory, infectious, and degenerative diseases almost entirely unstudied at systematic review scale.
- Several subspecialties are represented by a single model each in the meta-analysis — neuropathology, soft tissue and bone pathology, head and neck pathology, and paediatric pathology. Single-model estimates are not reliable basis for subspecialty-level conclusions.
- 52 of the 100 included studies could not be incorporated into the meta-analysis due to deficient data reporting — missing 2×2 contingency tables, incomplete performance metric reporting, or inadequate description of study populations. This is a substantial proportion of the evidence base effectively excluded from quantitative synthesis.
- Publication bias likely inflates the reported accuracy figures. Studies that find AI performs poorly are less likely to be published, meaning the literature disproportionately represents favorable results.
- The evidence base is geographically concentrated in the USA and China, raising questions about generalizability to health systems with different scanner hardware, staining protocols, and patient population characteristics.
Clinical Relevance: What This Review Supports and What It Does Not
Despite the high headline performance figures, routine clinical deployment of AI for whole slide image analysis remains rare. This gap is frequently attributed to technical barriers — infrastructure requirements, scanner interoperability, integration with laboratory information systems, and computational expertise. Those barriers are real. But the McGenity et al. review points to a more fundamental problem: the evidence base itself does not yet provide the quality of validation that routine clinical deployment requires.
What the review does support: proof-of-concept feasibility for AI-assisted diagnosis across multiple cancer types in whole slide images. The consistent pattern of high sensitivity across gastrointestinal, urological, and haematological pathology suggests that deep learning models can learn diagnostically meaningful tissue patterns. The performance advantage associated with external validation and multi-source training provides actionable design guidance for future studies.
What the review does not support: using aggregate sensitivity and specificity figures as benchmarks for procurement decisions, regulatory submissions, or clinical deployment justifications. A procurement team evaluating an AI pathology tool that cites 96% sensitivity should ask whether that figure comes from an internally validated single-institution study with non-consecutive case selection — which describes the majority of the underlying evidence — or from an externally validated multi-site prospective study, which describes very few.
- Ask whether the study used external validation on an independent dataset from a different institution or scanner environment.
- Ask whether cases were selected consecutively or whether the study used a curated case-control design that may inflate apparent accuracy.
- Ask how many data sources contributed to training and testing — single-source models show systematically lower performance when tested externally.
- Ask whether the study has been assessed for risk of bias using QUADAS-2 or a comparable framework, and what the results were.
- Ask whether the study population reflects the demographic and clinical characteristics of the patients in your setting.
Translation barriers extend beyond evidence quality. Standardization of image acquisition across different scanner manufacturers and resolutions remains unresolved. Annotated training datasets large enough to support generalizable models are scarce, particularly for rare diseases and non-cancer conditions. Computational expertise within pathology departments is limited. And the research generating this evidence is concentrated in high-income countries, raising equity concerns about whether AI tools developed and validated in resource-rich settings will perform equivalently in lower-resource clinical environments.
Study Limitations and Funding Disclosure
McGenity et al. declare several limitations that readers should hold alongside the findings:
- Search cutoff of June 2022 excludes post-2022 developments, including foundation model publications, prospective validation studies, and regulatory clearances issued from 2023 onward.
- Substantial heterogeneity in study design across included studies limits the interpretability of pooled estimates — the bivariate model accounts for some heterogeneity, but the underlying variation in study populations, AI architectures, and clinical tasks is substantial.
- Multiclass diagnostic tasks were collapsed to binary 2×2 contingency tables for meta-analysis, which may obscure performance variation across diagnostic categories within a single study.
- Many included studies had small test sets — the median test set size was 113 WSIs — which produces unstable performance estimates with wide confidence intervals.
The review was funded by the UK National Pathology Imaging Co-operative (NPIC), a £50 million investment from UK Research and Innovation. The authors declare no competing interests.
Companion Finding: AI for HER2 Classification in Breast Cancer
A second meta-analysis published in npj Digital Medicine (Albuquerque et al., 2025) extends the McGenity evidence base into a clinically urgent application: AI classification of HER2 immunohistochemistry scores in breast cancer. The clinical stakes here are concrete. The approval of trastuzumab deruxtecan (T-DXd) for HER2-low breast cancer has made accurate discrimination between HER2-zero and HER2-positive (1+, 2+, 3+) cases a treatment-determining task — and one where pathologist concordance has historically been limited.
Albuquerque et al. analyzed 13 studies contributing 25 contingency tables and 1,285 cases. For the T-DXd eligibility task — distinguishing HER2 scores of 1+, 2+, or 3+ from HER2-zero — the pooled sensitivity was 0.97 (95% CI 0.96–0.98) and specificity was 0.82 (95% CI 0.73–0.88), with an AUC of 0.98. These aggregate figures are high, but performance varied substantially by individual HER2 score category.
| HER2 Score Task | Sensitivity | Specificity | AUC |
|---|---|---|---|
| HER2 1+ detection | 0.69 (CI 0.57–0.79) | 0.94 | — |
| HER2 2+ detection | 0.89 | 0.96 | — |
| HER2 3+ detection | 0.97 | 0.99 | 1.00 |
| Overall T-DXd eligibility (1+/2+/3+ vs. 0) | 0.97 (CI 0.96–0.98) | 0.82 (CI 0.73–0.88) | 0.98 |
The sensitivity drop for HER2 1+ detection — 0.69 compared with 0.97 for HER2 3+ — is clinically significant. HER2 1+ is the boundary category for T-DXd eligibility, and a sensitivity of 0.69 means approximately 31% of HER2 1+ cases would be missed by AI classification at the aggregate level. This is precisely the boundary where accurate classification matters most for treatment decisions.
Meta-regression identified two additional patterns worth noting. Deep learning algorithms achieved significantly higher sensitivity than non-deep learning approaches (0.98 vs. 0.94). However, commercially available and externally validated algorithms underperformed experimental-only models — commercially available tools achieved sensitivity of 0.93 compared with 0.98 for experimental models, and externally validated algorithms showed sensitivity of 0.96 vs. 0.98 for those without external validation. This reversal — where external validation is associated with lower performance — may reflect the more challenging test conditions that external validation imposes, or it may reflect differences in the types of algorithms that have been commercially developed and independently validated to date.
Conference-level data from ASCO 2025 has suggested that AI assistance can improve pathologist concordance for HER2-low and HER2-ultralow scoring in multi-center settings. These reports require independent verification against primary publications before being treated as evidence — they are noted here as contextual 2025 developments, not as confirmed findings. The site's Q2 2026 Research Radar tracks ongoing HER2 AI and broader pathology AI developments as they emerge in the literature.
Source Citation and Study Record
Primary source: McGenity C, Cole AJ, Randell R, et al. Artificial intelligence in digital pathology: a systematic review and meta-analysis of diagnostic test accuracy. npj Digital Medicine. 2024. Available via Nature.com and PubMed Central (PMC11069583).
Companion source: Albuquerque C, et al. Systematic review and meta-analysis of artificial intelligence in classifying HER2 status in breast cancer immunohistochemistry. npj Digital Medicine. 2025. Available via Nature.com.
Comments
Join the discussion with an anonymous comment.