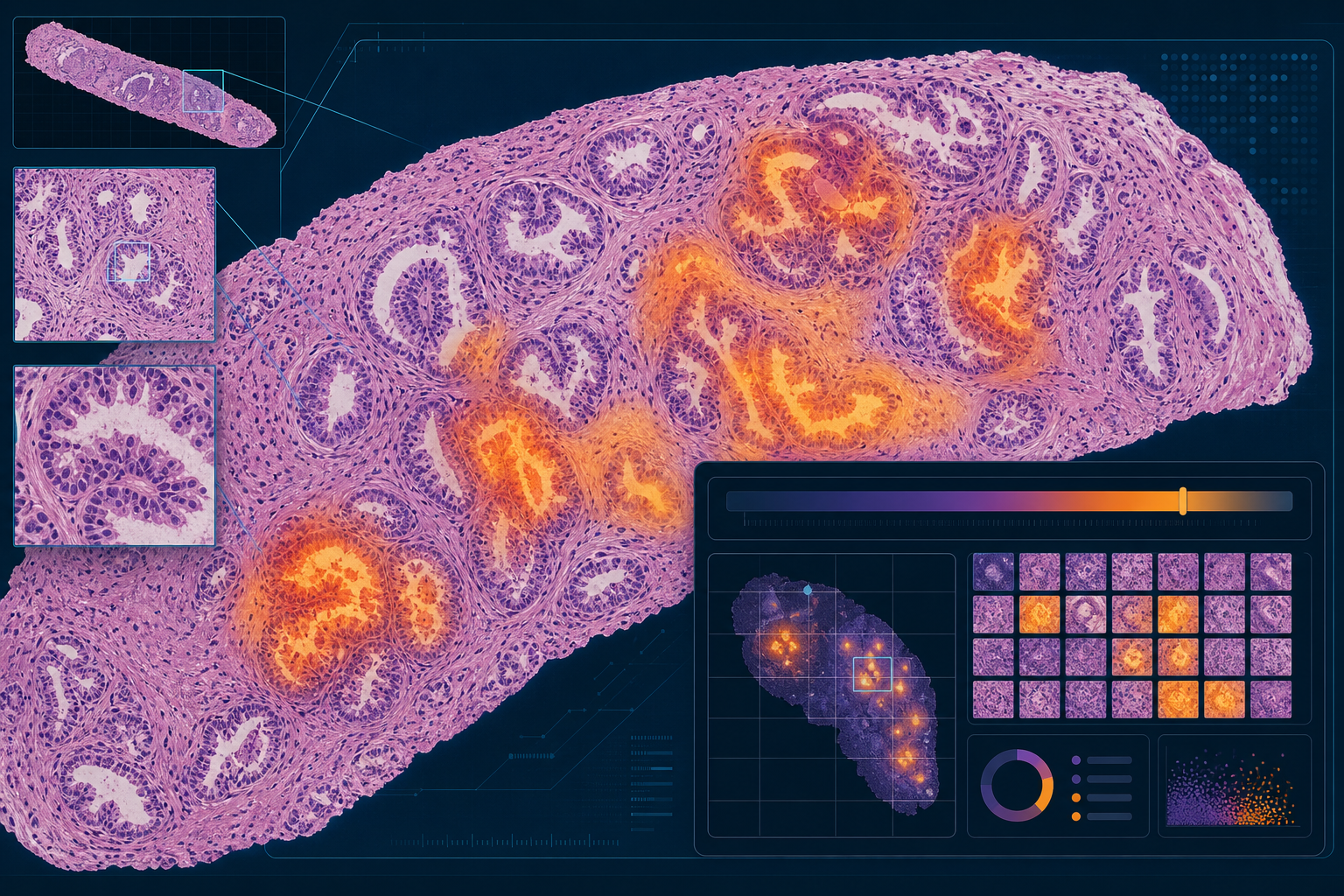
The Clinical Problem: Workforce Pressure and Diagnostic Variability in Pathology
The United States has approximately 16,200 practicing pathologists. According to workforce projections from the Health Resources and Services Administration (HRSA), that number is insufficient for the demand ahead: HRSA estimates a shortfall of roughly 4,230 pathology FTEs by 2037. The drivers are structural. An aging population is generating more cancer diagnoses and more chronic disease requiring tissue-based workup. Meanwhile, training supply is not keeping pace — in 2025, the number of pathology residency positions actually decreased by six slots despite a near-perfect match rate.
Rising biopsy volumes compound the staffing gap. Prostate, colorectal, cervical, and breast biopsies each represent high-volume, labor-intensive workflows where pathologists must examine and grade tissue at scale. Inter-observer variability in cancer grading — particularly Gleason scoring for prostate cancer — is well-documented in the literature. Even experienced pathologists disagree on grade group assignment in a meaningful proportion of cases, with consequences for treatment decisions ranging from active surveillance to radical prostatectomy.
These converging pressures — workforce contraction, volume growth, and diagnostic variability — are the clinical context that makes computational pathology worth examining seriously. AI tools that can reliably detect cancer on whole slide images, flag cases for review, or assist in grading have a plausible clinical rationale. The question is what the current evidence and regulatory record actually support.
What Computational Pathology Is: WSI Acquisition and AI Approaches
Computational pathology begins with digitization. A glass slide — prepared through standard histological processing, stained typically with hematoxylin and eosin (H&E) or immunohistochemical (IHC) stains — is placed in a whole slide imaging (WSI) scanner. The scanner captures the slide at high magnification across its entire surface, producing a gigapixel-scale digital image that can be examined on a computer screen with the same zoom, pan, and rotation capabilities a pathologist uses at the microscope.
The resulting files are large, typically ranging from 1 to 4 gigabytes per slide, and are stored in proprietary formats that vary by scanner manufacturer: Aperio SVS (Leica), Hamamatsu NDPI, and Philips iSyntax are the most common. This is a critical distinction from radiology. Radiology imaging has been standardized around the DICOM format since the 1990s, enabling interoperability across vendors and systems. Pathology WSI files remain largely in proprietary formats, with DICOM WSI adoption only partial as of 2026. This format fragmentation has direct consequences for AI deployment: a model trained on Aperio SVS files may not perform identically on Hamamatsu NDPI files from the same tissue type.
AI algorithms applied to WSIs generally fall into three categories:
- Patch-based deep learning: The gigapixel image is divided into smaller patches (typically 224×224 or 512×512 pixels). A convolutional neural network is trained to classify each patch — for example, as tumor or non-tumor. Patch-level predictions are then aggregated to produce a slide-level output. This approach requires annotated training data at the patch level.
- Multiple instance learning (MIL): The slide is treated as a "bag" of patches. The model learns from slide-level labels (e.g., cancer present or absent) without requiring patch-level annotations. An aggregation mechanism — attention pooling is common — weights patches by their contribution to the slide-level prediction. MIL reduces annotation burden and is well-suited to the weak-label settings common in pathology.
- Foundation models: Large models pretrained on hundreds of thousands of WSIs using self-supervised learning, capable of generating general-purpose slide representations that can be adapted to downstream tasks with limited labeled data. These are the most recent development and are currently research-stage tools without FDA authorization.
For pathologists and health system administrators evaluating these tools, the distinction between approaches matters less than the practical implications: what scanner does the algorithm require, what tissue types and stains was it trained on, and what clinical task does it perform? Those questions are answered by the FDA authorization record, not by the model architecture.

Clinical Use Cases by Subspecialty: Where the Evidence Is Strongest
The most comprehensive quantitative picture of AI performance across pathology subspecialties comes from a 2024 systematic review and meta-analysis published in npj Digital Medicine by McGenity et al. The review included 100 diagnostic accuracy studies applying AI to whole slide images, covering more than 152,000 WSIs. Using a bivariate random effects model, it estimated mean sensitivity of 96.3% (95% CI 94.1–97.7) and mean specificity of 93.3% (95% CI 90.5–95.4) across all included studies.
Performance varied substantially by subspecialty. Urological pathology — primarily prostate cancer detection and grading — showed the highest accuracy and the most developed evidence base. Gastrointestinal pathology followed closely. Breast pathology showed lower relative performance.
| Subspecialty | Mean Sensitivity | Mean Specificity | Primary Applications | Evidence Maturity |
|---|---|---|---|---|
| Urological (prostate) | 95% | 96% | Cancer detection, Gleason grade group classification | Most validated; most FDA-cleared tools |
| Gastrointestinal (colorectal, gastric) | 93% | 94% | Adenocarcinoma detection, polyp classification | Largest study subgroup in meta-analysis |
| Cervical cytology | Not separately reported in meta-analysis | Not separately reported | High-volume Pap test screening triage | Cleared tool (Hologic Genius); distinct cytology workflow |
| Breast pathology | 83% | 88% | Malignancy detection, HER2 scoring | Lower relative accuracy; fewer cleared tools |
Prostate cancer is the most mature application area for two compounding reasons: clinical need is high (Gleason grading variability directly affects treatment selection), and the tissue morphology of prostate glands is well-suited to pattern recognition at the cellular level. The McGenity meta-analysis finding that urological studies showed highest accuracy aligns with the regulatory record — two of the four contemporary FDA-authorized WSI AI tools are prostate-specific.
Cervical cytology occupies a distinct position. The Hologic Genius Cervical AI system operates on liquid-based cytology preparations rather than H&E tissue sections, making direct comparison with the McGenity meta-analysis accuracy figures inappropriate. The clinical rationale is volume-driven: cervical cytology screening generates extremely high case loads where AI-assisted prioritization and quality control can meaningfully reduce pathologist burden.
FDA-Authorized WSI AI Tools: What Is Actually Cleared as of Mid-2026
Through April 2026, the FDA has authorized 51 AI/ML-flagged devices across pathology-relevant review panels. Of those, only 7 algorithms actually analyze whole slide images. The remaining 44 are hematology analyzers, molecular IVDs, and cytology systems that do not perform WSI analysis. Of the 7 WSI AI devices, three are legacy IHC scoring systems authorized between 2004 and 2009 under older product codes. The four contemporary WSI AI tools are the clinically relevant set for this analysis.

| Product | Submission | Pathway | Auth. Date | Product Code | Indication | Scanner Constraint |
|---|---|---|---|---|---|---|
| Paige Prostate | DEN200080 | De Novo | September 2021 | QPN | Prostate cancer detection on H&E biopsy WSIs; flags slides for pathologist review | Specific compatible scanner models listed in label |
| Hologic Genius Cervical AI | DEN210035 | De Novo | January 2024 | QYV | Cervical cytology screening; prioritizes abnormal liquid-based cytology specimens | Hologic ThinPrep Imaging System; not a general WSI scanner |
| Ibex Galen Second Read | K241232 | 510(k) under QPN predicate | January 2025 | QPN | Prostate cancer detection; second-read AI for H&E biopsy WSIs | Scanner-specific per 510(k) label; verify K241232 directly for full list |
| ArteraAI Prostate | DEN240068 | De Novo | July 2025 | SFH | Prognostic prediction of androgen deprivation therapy benefit from H&E biopsy WSI combined with clinical data | Specific compatible scanner models listed in label |
Several features of this authorization set are worth noting explicitly. Paige Prostate (DEN200080) was the first WSI AI algorithm to receive De Novo authorization, in September 2021 — establishing the QPN product code that all subsequent prostate WSI AI submissions can use as a predicate. Ibex Galen Second Read (K241232) was the first 510(k) to use that QPN predicate, cleared in January 2025.
ArteraAI Prostate (DEN240068) represents a meaningful regulatory expansion: it is the first FDA-authorized WSI AI device cleared for a prognostic rather than purely diagnostic indication. Rather than detecting cancer presence or assigning a grade, it predicts which patients are likely to benefit from androgen deprivation therapy based on H&E biopsy morphology combined with clinical variables. This prognostic use case — predicting treatment response from tissue appearance — is a distinct regulatory category (product code SFH) that opens a new pathway for future submissions.
The Regulatory Pathway: Why WSI AI Is an IVD, Not SaMD
Understanding why WSI AI is regulated differently from radiology AI requires understanding how FDA classifies the underlying data. A digitized whole slide image is treated as a digital representation of a physical tissue specimen — the biological material that defines the in vitro diagnostic process. As a result, software that interprets that digital image is classified as an extension of the IVD process and reviewed in FDA's Office of Health Technology 7 (OHT7), which oversees in vitro diagnostics.
This contrasts with radiology AI, where the underlying data (CT, MRI, X-ray) is not a biological specimen — it is a physical measurement of the patient's body. Radiology AI algorithms are reviewed as Software as a Medical Device (SaMD) in OHT8. The IVD classification for WSI AI has several practical consequences:
- Clinical validation is specimen-aware: reviewers assess not just model performance metrics but the specific scanner models, stain protocols, tissue types, specimen preparation methods, and reader variability in ground truth labeling used in the validation study.
- Scanner-specific label restrictions are standard: each authorization specifies which scanner models are covered, because scanner hardware affects image characteristics in ways that can materially affect AI performance.
- The evidentiary bar reflects IVD precedent: the FDA's CDRH Digital Pathology Program has explicitly identified the lack of standardized test methods linking technical performance to clinical performance as a key regulatory science gap.
- Post-market surveillance obligations differ from SaMD: IVD post-market requirements include performance monitoring tied to the specific laboratory conditions covered by the authorization.
The three De Novo authorizations serve a specific structural function in this regulatory landscape. Each De Novo creates a new product code — QPN (Paige Prostate, 2021), QYV (Hologic Genius Cervical AI, 2024), and SFH (ArteraAI Prostate, 2025) — that defines the regulatory category and establishes the special controls applicable to that type of WSI AI device. Once a product code exists, subsequent manufacturers can use a cleared device as a predicate for a 510(k) submission rather than going through De Novo review. The Ibex Galen Second Read 510(k) (K241232, January 2025) is the first demonstration that this scaffolding works: it used the QPN predicate to achieve clearance through the more expedited 510(k) pathway.
Evidence Quality: What the Systematic Literature Actually Shows
The headline accuracy figures from the McGenity et al. 2024 systematic review — mean sensitivity 96.3%, mean specificity 93.3% — are frequently cited in discussions of AI pathology performance. They should be cited with the finding that immediately follows them in the same paper: 99% of the 100 included studies had at least one area at high or unclear risk of bias or applicability concerns.
The bias concerns identified by the review are not generic methodological complaints — they are specific patterns that directly affect how accuracy figures should be interpreted:
- Non-random or unclear case selection: Studies frequently selected cases in ways that enriched the dataset for positive findings, inflating sensitivity estimates.
- Absence of external validation: Models were often evaluated on held-out portions of the same dataset used for training, rather than on truly independent external cohorts.
- Mixing of training and test data: In some studies, the boundary between training and evaluation data was not clearly maintained, undermining the independence of performance estimates.
- Scanner homogeneity: Most studies used a single scanner platform, meaning reported accuracy figures do not generalize to other scanner types.
"Results for diagnostic accuracy need to be interpreted with caution" and "better quality study design, transparency, reporting quality and addressing substantial areas of bias is needed."
This conclusion from the McGenity review authors is consistent with findings from a separate 2024 review published in the same journal by Matthews et al., which examined 26 AI-based digital pathology products approved for the EEA/GB market. That review found that only 42% of products had peer-reviewed external validation studies, and that external validation data typically came from 1 to 3 sources scanned on 1 to 2 scanner platforms. Only 17% of published studies were independent of the product vendors.
The practical implication for clinicians and procurement teams is this: published accuracy figures for AI pathology tools — even figures from peer-reviewed studies — should be evaluated against the study design, not just the headline metric. Key questions include whether the model was externally validated, what scanner was used in the test set, and whether the study population reflects the demographics and tissue preparation protocols of the institution considering adoption.
Known Limitations: Scanner Lock, Stain Variability, and Demographic Bias
The limitations of WSI AI tools fall into two categories: those that apply universally to the field, and those specific to individual cleared tools. Both matter for adoption decisions.
- Scanner-specificity of cleared labels: Each FDA authorization specifies the scanner models covered. A tool cleared for use with Aperio AT2 slides is not necessarily cleared — or validated — for Hamamatsu NanoZoomer slides. Health systems with mixed scanner fleets face real constraints on which cleared tools they can deploy.
- Stain variability across labs: H&E staining protocols vary between institutions — staining duration, reagent brands, and tissue processing all affect image appearance. AI models trained on slides from one laboratory's protocol may show performance degradation when applied to slides from a different laboratory's protocol, even on the same scanner.
- Demographic and geographic bias in training data: Training datasets that underrepresent certain demographic groups, geographic regions, or tissue preparation practices may produce models that perform well in aggregate but poorly for specific patient populations. The Matthews et al. review explicitly notes that products tested on datasets with little diversity may hold limited value in real-world clinical practice.
- Performance degradation outside training distribution: AI models are generally most reliable when applied to cases resembling their training data. Unusual morphologies, rare subtypes, or tissue preparation artifacts not represented in training can degrade performance in ways that are not always visible to the pathologist reviewing the AI output.
- Proprietary format fragmentation: DICOM WSI adoption remains partial. The de facto file formats — Aperio SVS, Hamamatsu NDPI, Philips iSyntax — are proprietary, limiting interoperability between WSI platforms and complicating AI deployment across multi-vendor scanner environments.
Real-World Deployment Barriers: Why Most U.S. Labs Are Not Yet Ready
The existence of four FDA-authorized WSI AI tools does not mean that most U.S. pathology laboratories can immediately deploy them. The infrastructure gap is the primary constraint.
As of 2026, most U.S. pathology labs still use glass slides and optical microscopes for primary diagnosis. WSI scanning is used selectively — for teleconsultation, research, tumor boards, and specific computational use cases — but is not the default workflow for routine diagnostic sign-out in most community and regional hospitals. Radiology transitioned to fully digital acquisition in the mid-2000s; pathology has not completed an equivalent transition.
The scale comparison with other specialties illustrates the gap sharply. Cardiology AI cleared approximately 90 devices in 2025 alone. Pathology WSI AI has 7 cumulative authorizations across more than two decades of FDA review. This is not primarily a reflection of unmet clinical need — the workforce shortage and diagnostic variability problems are real. It reflects the compounding effect of several structural differences:
- WSI scanner infrastructure cost: High-throughput WSI scanners represent a capital investment that many community labs and smaller health systems have not made. Without scanner infrastructure, no cleared WSI AI tool can be deployed.
- IT storage and network requirements: Gigapixel WSI files require substantial storage capacity and high-speed internal networks. A busy pathology department generating thousands of slides per month produces terabytes of image data that must be stored, accessed, and backed up reliably.
- LIS and EHR integration complexity: AI-generated outputs must be integrated into the laboratory information system (LIS) and, where applicable, the EHR to be actionable. This integration requires technical work that varies substantially by LIS vendor and institutional IT environment.
- IVD validation cost burden: Laboratories deploying FDA-authorized IVDs are responsible for local validation studies demonstrating that the tool performs as claimed in their specific laboratory environment. This validation work — scanner, stain protocol, specimen type, reader cohort — represents a non-trivial cost that differs from the lighter-weight deployment validation typical of SaMD tools.
- Data standardization lag: The absence of universal DICOM WSI adoption means that AI tools are tied to specific scanner ecosystems rather than interoperable across platforms, limiting the addressable installed base for any single cleared tool.
Emerging Directions: Foundation Models and Prognostic AI
The research frontier in computational pathology has moved substantially beyond cancer detection toward two areas: foundation models trained on massive WSI datasets, and prognostic or predictive AI that moves from "is cancer present" to "what will happen to this patient."
The most prominent published example of a WSI foundation model is TITAN, described in a 2025 paper in Nature Medicine. TITAN was pretrained on 335,645 whole slide images across 20 organ types using visual self-supervised learning and vision-language alignment with pathology reports. Without fine-tuning on labeled clinical data, it can generate slide-level representations applicable to cancer subtyping, molecular classification, survival prediction, rare cancer retrieval, and pathology report generation. Other foundation models in the research literature include UNI, CONCH, and GigaPath.
The prognostic direction is where regulated clinical deployment is beginning to expand. ArteraAI Prostate (DEN240068), authorized by FDA in July 2025, is the first cleared example: it predicts which prostate cancer patients are likely to benefit from androgen deprivation therapy based on H&E biopsy morphology combined with clinical data. This is a fundamentally different task from cancer detection — it requires the AI to capture tissue features associated with treatment response rather than malignancy presence, and it requires a different evidence standard to establish clinical utility.
The regulatory expansion from detection to prognosis (QPN → SFH product code) signals that FDA's IVD review framework can accommodate more complex clinical questions as the evidence base develops. Whether the foundation model research translates to cleared prognostic or predictive tools will depend on whether developers can meet the specimen-aware validation requirements — scanner-specific, stain-specific, population-specific — that the IVD pathway requires.
- Cancer subtyping and molecular classification from H&E morphology alone — reducing or eliminating the need for molecular testing in some settings.
- Biomarker prediction (e.g., MSI status, HER2 amplification, BRCA mutation) from tissue images, potentially enabling treatment selection without additional molecular assays.
- Survival prediction and risk stratification integrated into pathology reporting.
- Multimodal AI combining WSI with genomics, radiology, and clinical data — currently in research phase with no cleared multimodal pathology AI as of mid-2026.
Procurement Considerations: Questions to Ask Before Adoption
For pathologists and health system administrators moving from awareness to evaluation, the following structured questions frame the due diligence process. This is not a vendor recommendation — it is a checklist of the questions the regulatory record and evidence literature indicate are material to a sound adoption decision.
| Evaluation Dimension | Key Question | Why It Matters |
|---|---|---|
| Scanner compatibility | Is our specific scanner model explicitly listed in the FDA-cleared label for this tool? | Operating outside the cleared scanner specification is off-label use; scanner affects image characteristics that directly affect AI performance |
| Evidence base | Is there peer-reviewed external validation — not just internal validation — published for this tool? | Internal validation on the training dataset overstates real-world performance; external validation on independent cohorts is the relevant signal |
| Validation dataset demographics | What patient population, institution, and geographic region were used in the validation dataset? | Models tested on homogeneous datasets may underperform in demographically or geographically distinct patient populations |
| Stain protocol compatibility | Were the validation studies conducted with stain protocols comparable to our laboratory's? | Stain variability is a documented source of AI performance degradation across institutions |
| Specimen types covered | What biopsy types, tissue preparation methods, and specimen sources are covered by the cleared indication? | The cleared indication specifies the scope of use; applying the tool outside that scope is off-label |
| LIS/EHR integration | How does the tool integrate with our LIS and, if applicable, our EHR? What is the integration pathway? | AI outputs must be actionable within the clinical workflow; standalone tools with no LIS integration create manual transcription burden |
| Local validation requirements | What laboratory validation is required before clinical deployment, and what are the associated costs? | FDA-authorized IVDs require local validation studies; this cost and effort should be factored into the adoption decision |
| Post-market surveillance | What post-market performance monitoring does the cleared label require, and who is responsible for it? | IVD post-market obligations apply to the laboratory deploying the tool, not only to the manufacturer |
| Prognostic vs. diagnostic indication | Is this tool cleared for detection/grading, or for prognostic prediction? What clinical workflow does each support? | Detection and prognostic tools require different clinical integration points and evidence standards for utility |
One additional consideration applies specifically to institutions without existing WSI infrastructure: the AI tool decision cannot be separated from the scanner infrastructure decision. Selecting a cleared WSI AI tool before selecting a scanner — or selecting a scanner without verifying compatibility with cleared AI tools of interest — creates constraints that are difficult to reverse.
Comments
Join the discussion with an anonymous comment.