The ED Chest X-Ray Challenge: Volume, Availability Gaps, and Triage Scale Limitations
Chest X-ray is one of the highest-volume imaging studies ordered in emergency departments. It is frequently the first imaging step for patients presenting with dyspnea, chest pain, fever, or trauma — conditions where time-to-diagnosis directly affects clinical outcomes. The volume pressure is compounded by a structural problem: radiologist availability is uneven across the day, and off-hours coverage in many health systems is provided by a reduced number of on-call readers handling a compressed queue.
Conventional triage systems such as the Korean Triage and Acuity Scale (KTAS) or the Emergency Severity Index (ESI) stratify patients using presenting symptoms, vital signs, and clinical assessment. These scales were not designed to incorporate imaging findings. A patient may be assigned a moderate acuity score on presentation and then found to have a significant radiographic abnormality — but the imaging result arrives after the triage decision has already shaped bed assignment and care sequencing.
This creates two distinct unmet needs. First, radiologists need a mechanism to ensure that the most urgent studies in a high-volume queue are read first — a workflow efficiency problem. Second, emergency physicians need imaging information integrated into triage decision-making earlier in the patient encounter — a clinical decision support problem. These are related but fundamentally different requirements, and the AI tools designed to address them are not interchangeable.
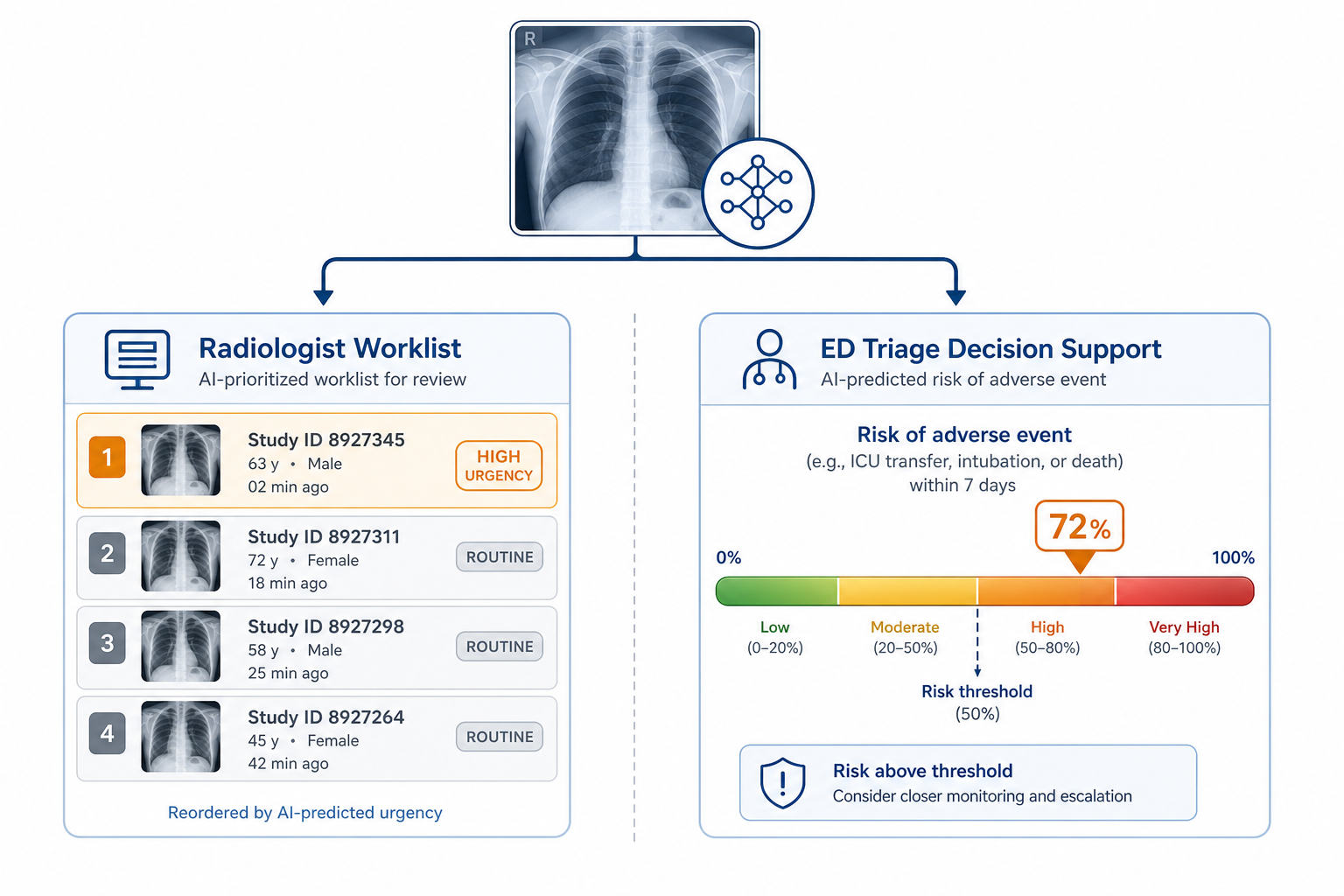
Two Distinct AI Roles: Worklist Prioritization vs. Adverse Event Prediction
The most consequential planning error in evaluating AI chest X-ray tools for the ED is treating these two functions as a single capability. They are not. Each role has its own evidence base, its own FDA-cleared products, and its own set of deployment requirements.

Role 1 — Worklist Prioritization: The AI system analyzes incoming chest X-rays and reorders the radiologist reading queue by urgency. Studies flagged as likely to contain critical or urgent findings are elevated to the top of the worklist. The radiologist still reads and reports every study; the AI changes the sequence, not the clinical decision. This is the Computer-Aided Triage (CADt) model.
Role 2 — Adverse Event Prediction: The AI system generates a risk score from the chest X-ray image that predicts the probability of a major adverse cardiopulmonary event — hospitalization, ED revisit, or death. This score is intended to inform the emergency physician's triage decision, functioning as a supplementary input alongside conventional symptom-based acuity scales. The end-user is the ED clinician, not the radiologist.
| Dimension | Role 1: Worklist Prioritization | Role 2: Adverse Event Prediction |
|---|---|---|
| Primary end-user | Radiologist | Emergency physician |
| Function | Reorders reading queue by urgency | Generates risk score for triage decision support |
| Clinical output | Study prioritization signal | Probability of major adverse cardiopulmonary event |
| Integration point | PACS / radiology worklist | ED triage workflow / EHR |
| Key metric | Turnaround time (TAT) reduction | AUC vs. conventional triage scale |
| Primary evidence | Prospective real-world study (n=20,944) | Retrospective cohort study (n=3,576) |
| FDA-cleared example | Lunit INSIGHT CXR Triage (K211733) | No dedicated clearance for adverse event prediction role identified |
Evidence for Role 1 — Worklist Prioritization: Real-World TAT Reduction and Its Limits

The strongest prospective evidence for AI CXR worklist prioritization comes from a real-world study at Changi General Hospital in Singapore involving 20,944 chest X-rays evaluated using Lunit INSIGHT CXR Triage. The study reported a 77% reduction in turnaround time across all patient subgroups. For urgent CXRs, the system achieved 82% sensitivity at 99% specificity. For normal CXRs, sensitivity reached 89% with 93% specificity. Subgroup analyses across age groups, genders, and four ethnic groups showed consistently high accuracy, with sensitivity, specificity, and AUC above 84% in each subgroup — a meaningful finding for health systems serving diverse patient populations.
The study used an observational design with 43 radiologists blinded to AI results, assessing a three-tier classification of normal, non-urgent, and urgent. The prospective design is a significant methodological strength relative to the retrospective studies that dominate this literature.
Why Workflow Parameters Predict Time Savings Better Than Model AUC
A 77% TAT reduction is a striking figure, but its applicability to any given ED depends heavily on local workflow conditions — not on the AI model's performance characteristics alone. Research from the FDA's Center for Devices and Radiological Health and the University of Chicago, using the QuCAD computational modeling framework applied to CT pulmonary angiography exams for pulmonary embolism, provides a methodological framework for understanding this dependency.
The QuCAD framework demonstrates that the primary determinants of AI triage time savings are not the model's AUC but rather: the number of radiologists on shift, the rate at which new exams arrive (inter-arrival time), how long radiologists take to read each study, and the prevalence of the target condition in the imaging population. When radiologist capacity is high relative to exam volume — as is more likely off-hours when both exam volume and staffing are reduced — AI-driven queue reordering produces smaller absolute gains. Adding a single radiologist to a shift can reduce AI-driven TAT savings to near zero.
This has a direct implication for ED deployment planning: the same AI tool may deliver meaningful TAT benefit during peak daytime hours when exam volume is high and the queue is genuinely congested, while producing minimal benefit during overnight shifts when the queue is shorter and coverage is already thin. Evaluating AI CXR triage on average TAT across all hours will obscure this asymmetry.
Broader evidence on AI efficiency in medical imaging reinforces caution. A 2024 systematic review and meta-analysis in npj Digital Medicine examined 48 real-world clinical AI imaging studies and found that while 67% of studies reporting time-for-task outcomes showed reductions, three separate meta-analyses of 12 comparable studies showed no statistically significant efficiency effects after AI implementation, with high heterogeneity across studies. More than half of the included studies had relevant conflicts of interest. The review's conclusion — that robust inferences about real-world AI efficiency benefits in imaging remain limited — is important context for any single-center TAT finding, including the Changi General Hospital result.
Evidence for Role 2 — Adverse Event Prediction: AI vs. KTAS for Major Cardiopulmonary Events
The evidence for using AI chest X-ray analysis to predict major adverse cardiopulmonary events in ED patients comes primarily from a 2025 study published in Korean Journal of Radiology by Rhee et al. at Seoul National University Hospital. The study enrolled 3,576 ED patients presenting with acute cardiopulmonary symptoms and assessed whether AI analysis of their chest X-rays could predict a composite endpoint of hospitalization, ED revisit within 30 days, or death.
The study's primary finding was a substantial AUC advantage for AI over KTAS: 0.795 versus 0.610 (P<0.001). At a 15% score threshold, the AI system achieved 92.4% sensitivity and 38.4% specificity for predicting major adverse events. Critically, AI results remained an independent predictor of adverse events after statistical adjustment for KTAS score, with an adjusted odds ratio of 6.913 for scores at or above the 15% threshold. A combination model incorporating both AI and KTAS achieved AUC 0.799 — outperforming KTAS alone but similar to AI alone, suggesting that AI captures information largely orthogonal to what symptom-based triage measures.
Performance was consistent across fixed and portable scanner subgroups, and in patients presenting with fever or dyspnea — a finding relevant to EDs where portable imaging is common and patient acuity varies widely.
| Metric | AI (Lunit INSIGHT CXR) | KTAS | Combination Model |
|---|---|---|---|
| AUC | 0.795 | 0.610 | 0.799 |
| Sensitivity (at 15% threshold) | 92.4% | — | — |
| Specificity (at 15% threshold) | 38.4% | — | — |
| Independent predictor after KTAS adjustment | Yes (adjusted OR 6.913) | Reference | — |
The study's authors draw an explicit boundary around these findings: AI chest X-ray analysis cannot replace conventional triage because critical emergencies such as acute coronary syndrome may present with a normal or near-normal chest X-ray. The AI score reflects what is visible on the image; it cannot detect conditions that are not radiographically apparent. The authors position AI as a supplementary tool that adds predictive value on top of — not instead of — symptom-based assessment.
FDA Regulatory Context: CADt Clearances with ED-Specific Indications
Two vendors hold FDA authorizations with direct relevance to AI chest X-ray triage in the ED. Understanding what each clearance specifically covers — and what it does not — is essential for procurement and deployment planning. For readers unfamiliar with the regulatory pathway, the 510(k) substantial equivalence framework for AI-enabled SaMD is explained in the site glossary. For the broader landscape of FDA-cleared radiology AI devices, see FDA-Cleared Radiology AI: Mapping the Landscape and the Clinical Evidence Gap.
Lunit INSIGHT CXR Triage — K211733
Lunit received FDA 510(k) clearance for Lunit INSIGHT CXR Triage in November 2021 under submission number K211733. The clearance specifically covers the sorting of emergency cases found on chest X-rays — making it one of the few chest X-ray AI tools with an ED-specific indication rather than a general radiology reading assistance indication. The product was introduced to the US market at RSNA 2021 in partnership with GE Healthcare, Philips, and FujiFilm.
Qure.ai qXR-Detect — 26 FDA-Cleared Indications
Qure.ai's qXR-Detect holds 26 FDA-cleared indications as of February 2026, including triage and notification indications for pneumothorax and pleural effusion — findings with direct ED urgency implications. The product is described as a CADe solution supporting emergency room physicians, family medicine practitioners, and radiologists across six anatomical regions. Notably, qXR-Detect is currently the only chest X-ray CADe device cleared with a Predetermined Change Control Plan (PCCP), which enables algorithm updates within defined parameters without requiring a new 510(k) submission — a meaningful consideration for long-term software maintenance in clinical deployment.
Evidence Quality and Study Limitations
The current evidence base for AI CXR triage in the ED has meaningful strengths — particularly the prospective design and scale of the Changi General Hospital study — but carries significant limitations that any deployment decision must account for.
A 2024 scoping review of 29 US ED AI triage studies found that all 29 studies used retrospective data. None of the studies in that review specifically examined chest X-ray AI as the triage input — they covered clinical data ML models broadly — but the pattern of retrospective-only validation is consistent with the wider AI ED triage literature. Prospective validation in diverse, real-world ED populations remains limited.
- No RCT evidence demonstrates improved patient-level outcomes — mortality, ED length of stay — from AI CXR triage in the emergency department specifically. This gap must be explicitly acknowledged in any deployment justification.
- Single-center study concentration limits generalizability. The Changi General Hospital study is a prospective exception, but it represents one institution in one health system.
- Demographic bias risk: documented racial and gender performance disparities have been identified on public CXR datasets. The Changi study's subgroup analysis across ethnic groups is encouraging but does not resolve the broader concern across different training populations.
- Portable vs. fixed scanner performance gap: while the KJR 2025 study found consistent performance across scanner types, this cannot be assumed to generalize across all AI CXR tools or all ED environments.
- High false-positive burden at high sensitivity thresholds: achieving 92.4% sensitivity for adverse event prediction at a 15% score threshold comes with 61.6% false positives. Alert fatigue and unnecessary clinical escalation are real operational risks.
- Disease prevalence effects: the magnitude of workflow benefit from worklist prioritization is sensitive to the prevalence of urgent findings in the local imaging population. A tool calibrated for a high-acuity tertiary ED may perform differently in a community ED with different case mix.
- Meta-analytic null finding: despite 67% of individual studies reporting efficiency gains, three meta-analyses in the npj Digital Medicine 2024 review found no statistically significant effects across comparable studies, with high heterogeneity. Individual study results should be interpreted against this aggregate context.
Deployment Requirements: What Real-World ED Integration Actually Demands
FDA clearance and a favorable single-center study are not sufficient conditions for successful ED deployment. The npj Health Systems 2026 overview of AI chest radiography identifies PACS integration and EHR workflow connection as persistent barriers to routine clinical deployment, alongside generalizability concerns and black-box interpretability. Real-world deployment requires addressing each of these conditions before go-live.
| Deployment Requirement | Role 1: Worklist Prioritization | Role 2: Adverse Event Prediction |
|---|---|---|
| Primary integration point | PACS / radiology information system | ED triage workflow / EHR |
| Alert delivery mechanism | Radiologist worklist reordering | ED physician notification or EHR flag |
| Alert fatigue risk | Moderate (flagged studies at top of queue) | High (92.4% sensitivity = many alerts) |
| Site calibration needed | Threshold tuning by exam volume, staffing | Threshold tuning by local adverse event prevalence |
| End-user training | Radiologists and PACS administrators | ED nurses, physicians, and triage staff |
| Post-deployment monitoring | TAT tracking, override rate, drift surveillance | Alert response rate, clinical outcome tracking |
PACS Integration and Technical Barriers
Connecting an AI CXR triage tool to an existing radiology workflow requires the AI output to be routed into the PACS worklist in real time. This is technically non-trivial: PACS systems vary considerably in their support for third-party AI integrations, and the latency between image acquisition and AI output must be low enough to influence reading order before the radiologist has already begun working through the queue manually. Health systems with older PACS infrastructure or fragmented imaging environments face higher integration overhead.
Alert Design and Threshold Calibration
The operating threshold for any AI CXR triage tool is a deployment decision, not a fixed product specification. Setting a high sensitivity threshold captures more urgent cases but generates more false positives. In a worklist prioritization context, over-flagging degrades the radiologist's trust in the system and may lead to de facto ignoring of priority signals. In an adverse event prediction context, high alert rates create alert fatigue for ED nurses and physicians and may prompt inappropriate escalation for patients who do not require it. Site-specific threshold calibration — based on local disease prevalence, staffing patterns, and clinical risk tolerance — is required before routine use.
Site-Specific Workflow Calibration
The workflow parameter modeling framework described earlier has a direct operational implication: health systems should model expected TAT benefit under their own staffing and volume conditions before committing to a worklist prioritization deployment. A system with two overnight on-call radiologists covering a low-volume ED may see minimal benefit from AI queue reordering. The same tool at a high-volume academic ED with daytime imaging peaks may produce substantial gains during those peak periods. Deployment planning that assumes the Changi General Hospital TAT result will replicate locally is a planning risk.
Post-Deployment Monitoring
AI model performance can drift as patient population characteristics, imaging equipment, and clinical practices change over time. Post-deployment monitoring should track AI alert accuracy against confirmed clinical outcomes, radiologist override rates (a proxy for trust calibration), and any changes in case mix that may shift the tool's operating conditions outside the range of its training data. The presence of a PCCP in Qure.ai's clearance reflects FDA recognition that ongoing algorithm updates are a feature of deployed AI SaMD — not a one-time validation event.
Clinical Takeaways for ED and Radiology Decision-Makers
- Establish which role the tool fills before evaluation. Worklist prioritization and adverse event prediction are separate functions with separate evidence bases, separate FDA-cleared products, and separate integration requirements. The pre-deployment question is not 'which AI CXR tool is best' but 'which clinical problem are we solving and which role addresses it.'
- The strongest prospective evidence for worklist prioritization (77% TAT reduction, n=20,944) comes from a single institution in Singapore. It is the best available real-world data, but its applicability depends on local workflow parameters — radiologist count, exam volume, and disease prevalence — not on the AI model's AUC alone.
- TAT savings from AI worklist prioritization are likely to be significant during high-volume daytime hours and non-significant or minimal during off-hours when queue congestion is lower. Deployment planning should account for this asymmetry explicitly.
- For adverse event prediction, AI CXR analysis significantly outperformed KTAS (AUC 0.795 vs. 0.610) as an independent predictor of major cardiopulmonary events in a 3,576-patient ED study. AI adds predictive information that KTAS does not capture — but it cannot substitute for conventional triage because CXR-negative emergencies exist.
- The KJR 2025 adverse event prediction evidence used Lunit INSIGHT CXR v3.1.4.1 — the general interpretation tool — not Lunit INSIGHT CXR Triage (K211733), the FDA-cleared worklist prioritization product. These are distinct products and the evidence supporting each must be evaluated independently.
- FDA clearance confirms regulatory authorization for a specific intended use. It does not confirm reimbursement coverage, real-world US ED deployment outcomes, or performance equivalence across health systems with different patient populations and imaging environments.
- No RCT evidence currently demonstrates that AI CXR triage improves patient-level outcomes — mortality or ED length of stay — in the emergency department. The evidence supports workflow efficiency and predictive accuracy under specific conditions; patient outcome benefit remains unproven.
- Successful deployment requires site-specific threshold calibration, PACS or EHR integration planning appropriate to the tool's role, clinician training for the relevant end-users (radiologists for Role 1, ED physicians and nurses for Role 2), and ongoing post-deployment performance monitoring.
Comments
Join the discussion with an anonymous comment.